原文:https://www.qcloud.com/community/article/129
一、综述
memcached和redis就是将数据存储在内存中,按照key-value的方式查询,可以大幅度提高效率。所以一般它们都用做缓存服务器,缓存常用的数据,需要查询的时候,直接从它们那儿获取,减少查询数据库的次数,提高查询效率。
二、服务方式
memcached和redis自己本身就是网络服务器,用户进程通过与他们通过网络来传输数据,显然最简单和最常用的就是使用tcp连接了。另外,memcached和redis都支持udp协议。而且当用户进程和memcached和redis在同一机器时,还可以使用unix域套接字通信。
三、事件模型
redis的事件模型很简单,只有一个event loop,是简单的reactor实现。
而memcached是多线程的,使用master-worker的方式,主线程监听端口,建立连接,然后顺序分配给各个工作线程。每一个从线程都有一个event loop,它们服务不同的客户端。
多线程的优势就是可以充分发挥多核的优势,不过编写程序麻烦一点,memcached里面就有各种锁和条件变量来进行线程同步。
四、内存分配
memcached和redis的核心任务都是在内存中操作数据,内存管理自然是核心的内容。
- memcached是有自己得内存池的,即预先分配一大块内存,然后接下来分配内存就从内存池中分配,这样可以减少内存分配的次数,提高效率,这也是大部分网络服务器的实现方式,只不过各个内存池的管理方式根据具体情况而不同。
- redis没有自己得内存池,而是直接使用时分配,即什么时候需要什么时候分配,内存管理的事交给内核,自己只负责取和释放。不过redis支持使用tcmalloc来替换glibc的malloc,前者是google的产品,比glibc的malloc快。
redis既是单线程,又没有自己的内存池,是不是感觉实现的太简单了?那是因为它的重点都放在数据库模块了
由于redis没有自己的内存池,所以内存申请和释放的管理就简单很多,直接malloc和free即可,十分方便。而memcached是支持内存池的,所以内存申请是从内存池中获取,而free也是还给内存池,所以需要很多额外的管理操作,实现起来麻烦很多
五、数据库实现
1. memcached数据库实现
memcached只支持key-value,即只能一个key对于一个value。它的数据在内存中也是这样以key-value对的方式存储,它使用slab机制。
每一个key-value对都存储在一个item结构中,包含了相关的属性和key和value的值。
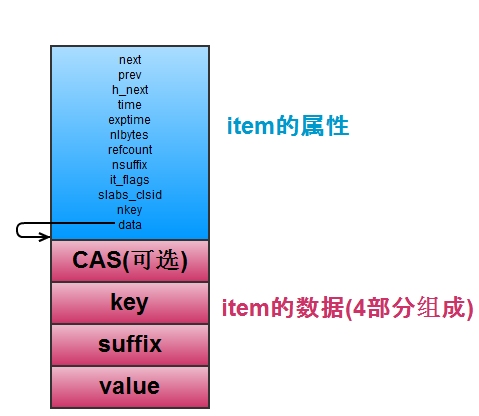
item是保存key-value对的,当item多的时候,怎么查找特定的item是个问题。所以memcached维护了一个hash表,它用于快速查找item。hash表使用开链法(与redis一样)解决键的冲突,每一个hash表的桶里面存储了一个链表,链表节点就是item的指针,如上图中的h_next就是指桶里面的链表的下一个节点。
memcached支持设置过期时间,即expire time,但是内部并不定期检查数据是否过期,而是客户进程使用该数据的时候,memcached会检查expire time,如果过期,直接返回错误。这样的优点是,不需要额外的cpu来进行expire time的检查,缺点是有可能过期数据很久不被使用,则一直没有被释放,占用内存。
memcached是多线程的,而且只维护了一个数据库,所以可能有多个客户进程操作同一个数据,这就有可能产生问题。比如,A已经把数据更改了,然后B也更改了改数据,那么A的操作就被覆盖了,而可能A不知道,A任务数据现在的状态时他改完后的那个值,这样就可能产生问题。为了解决这个问题,memcached使用了CAS协议,简单说就是item保存一个64位的unsigned int值,标记数据的版本,每更新一次(数据值有修改),版本号增加,然后每次对数据进行更改操作,需要比对客户进程传来的版本号和服务器这边item的版本号是否一致,一致则可进行更改操作,否则提示脏数据。
2. redis数据库实现
redis数据库的功能强大一些,因为不像memcached只支持保存字符串,redis支持string, list, set,sorted set,hash table 5种数据结构。
为了实现这些数据结构,redis定义了抽象的对象redis object,如下图。每一个对象有类型,一共5种:字符串,链表,集合,有序集合,哈希表。 同时,为了提高效率,redis为每种类型准备了多种实现方式,根据特定的场景来选择合适的实现方式,encoding就是表示对象的实现方式的。
然后还有记录了对象的lru,即上次被访问的时间,同时在redis 服务器中会记录一个当前的时间(近似值,因为这个时间只是每隔一定时间,服务器进行自动维护的时候才更新),它们两个只差就可以计算出对象多久没有被访问了。
然后redis object中还有引用计数,这是为了共享对象,然后确定对象的删除时间用的。
最后使用一个void*指针来指向对象的真正内容。正式由于使用了抽象redis object,使得数据库操作数据时方便很多,全部统一使用redis object对象即可,需要区分对象类型的时候,再根据type来判断。而且正式由于采用了这种面向对象的方法,让redis的代码看起来很像c++代码,其实全是用c写的。
typedef struct redisObject {
unsigned type:4; // 对象的类型,包括 /* Object types */
unsigned encoding:4; // 底部为了节省空间,一种type的数据,可以采用不同的存储方式
unsigned lru:REDIS_LRU_BITS;// lru time (relative to server.lruclock)
int refcount; // 引用计数
void *ptr;
}
说到底redis还是一个key-value的数据库,不管它支持多少种数据结构,最终存储的还是以key-value的方式,只不过value可以是链表,set,sorted set,hash table等。
和memcached一样,所有的key都是string,而set,sorted set,hash table等具体存储的时候也用到了string。 而c没有现成的string,所以redis的首要任务就是实现一个string,取名叫sds(simple dynamic string),如下的代码, 非常简单的一个结构体,len存储改string的内存总长度,free表示还有多少字节没有使用,而buf存储具体的数据,显然len-free就是目前字符串的长度。
struct sdshdr {
int len;
int free;
char buf[];
} robj;
key和value的关联:C没有字典,redis自己造了一个轮子。如下面代码,privdata存额外信息,用的很少,至少我们发现。 dictht是具体的哈希表,一个dict对应两张哈希表,这是为了扩容(包括rehashidx也是为了扩容)。dictType存储了哈希表的属性。redis还为dict实现了迭代器(所以说看起来像c++代码)。
typedef struct dict {
dictType *type; // 哈希表的相关属性
void *privdata; // 额外信息
dictht ht[2]; // 两张哈希表,分主和副,用于扩容
int rehashidx; /* rehashing not in progress if rehashidx == -1 */ // 记录当前数据迁移的位置,在扩容的时候用的
int iterators; /* number of iterators currently running */ // 目前存在的迭代器的数量
} dict;
typedef struct dictht {
dictEntry **table; // dictEntry是item,多个item组成hash桶里面的链表,table则是多个链表头指针组成的数组的指针
unsigned long size; // 这个就是桶的数量
// sizemask取size - 1, 然后一个数据来的时候,通过计算出的hashkey, 让hashkey & sizemask来确定它要放的桶的位置
// 当size取2^n的时候,sizemask就是1...111,这样就和hashkey % size有一样的效果,但是使用&会快很多。这就是原因
unsigned long sizemask;
unsigned long used; // 已经数值的dictEntry数量
} dictht;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); // hash的方法
void *(*keyDup)(void *privdata, const void *key); // key的复制方法
void *(*valDup)(void *privdata, const void *obj); // value的复制方法
int (*keyCompare)(void *privdata, const void *key1, const void *key2); // key之间的比较
void (*keyDestructor)(void *privdata, void *key); // key的析构
void (*valDestructor)(void *privdata, void *obj); // value的析构
} dictType;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
struct dictEntry *next;
} dictEntry;
一个dict对于两个dictht,是为了扩容(其实还有缩容)。正常的时候,dict只使用dictht[0],当dict[0]中已有entry的数量与桶的数量达到一定的比例后,就会触发扩容和缩容操作,我们统称为rehash,这时,为dictht[1]申请rehash后的大小的内存,然后把dictht[0]里的数据往dictht[1]里面移动,并用rehashidx记录当前已经移动万的桶的数量,当所有桶都移完后,rehash完成,这时将dictht[1]变成dictht[0], 将原来的dictht[0]变成dictht[1],并变为null即可。不同于memcached,这里不用开一个后台线程来做,而是就在event loop中完成,并且rehash不是一次性完成,而是分成多次,每次用户操作dict之前,redis移动一个桶的数据,直到rehash完成。这样就把移动分成多个小移动完成,把rehash的时间开销均分到用户每个操作上,这样避免了用户一个请求导致rehash的时候,需要等待很长时间,直到rehash完成才有返回的情况。不过在rehash期间,每个操作都变慢了点,而且用户还不知道redis在他的请求中间添加了移动数据的操作。
有了dict,数据库就好实现了。所有数据读存储在dict中,key存储成dictEntry中的key(string),用void* 指向一个redis object,它可以是5种类型中的任何一种。
与memcached不同的是,redis的数据库不止一个,默认就有16个,编号0-15。客户可以选择使用哪一个数据库,默认使用0号数据库。 不同的数据库数据不共享,即在不同的数据库中可以存在同样的key,但是在同一个数据库中,key必须是唯一的。
redis也支持expire time的设置,我们看上面的redis object,里面没有保存expire的字段,那redis怎么记录数据的expire time呢? redis是为每个数据库又增加了一个dict,这个dict叫expire dict,它里面的dict entry里面的key就是数对的key,而value全是数据为64位int的redis object,这个int就是expire time。这样,判断一个key是否过期的时候,去expire dict里面找到它,取出expire time比对当前时间即可。为什么这样做呢? 因为并不是所有的key都会设置过期时间,所以,对于不设置expire time的key来说,保存一个expire time会浪费空间,而是用expire dict来单独保存的话,可以根据需要灵活使用内存(检测到key过期时,会把它从expire dict中删除)。
redis的expire 机制是怎样的呢? 与memcahed类似,redis也是惰性删除,即要用到数据时,先检查key是否过期,过期则删除,然后返回错误。单纯的靠惰性删除,上面说过可能会导致内存浪费,所以redis也有补充方案,redis里面有个定时执行的函数,叫servercron,它是维护服务器的函数,在它里面,会对过期数据进行删除,注意不是全删,而是在一定的时间内,对每个数据库的expire dict里面的数据随机选取出来,如果过期,则删除,否则再选,直到规定的时间到。即随机选取过期的数据删除,这个操作的时间分两种,一种较长,一种较短,一般执行短时间的删除,每隔一定的时间,执行一次长时间的删除。这样可以有效的缓解光采用惰性删除而导致的内存浪费问题。
3. redis数据库持久化
redis和memcached的最大不同,就是redis支持数据持久化。
3.1 RDB持久化
用户执行save或者bgsave的时候,就会触发RDB持久化操作。RDB持久化操作的核心思想就是把数据库原封不动的保存在文件里。
保存了RDB文件,当redis再启动的时候,就根据RDB文件来恢复数据库。由于以及在RDB文件中保存了数据库的号码,以及它包含的key-value对,以及每个key-value对中value的具体类型,实现方式,和数据,redis只要顺序读取文件,然后恢复object即可。由于保存了expire time,发现当前的时间已经比expire time大了,即数据已经超时了,则不恢复这个key-value对即可。
保存RDB文件是一个很巨大的工程,所以redis还提供后台保存的机制。即执行bgsave的时候,redis fork出一个子进程,让子进程来执行保存的工作,而父进程继续提供redis正常的数据库服务。由于子进程复制了父进程的地址空间,即子进程拥有父进程fork时的数据库,子进程执行save的操作,把它从父进程那儿继承来的数据库写入一个temp文件即可。在子进程复制期间,redis会记录数据库的修改次数(dirty)。当子进程完成时,发送给父进程SIGUSR1信号,父进程捕捉到这个信号,就知道子进程完成了复制,然后父进程将子进程保存的temp文件改名为真正的rdb文件(即真正保存成功了才改成目标文件,这才是保险的做法)。然后记录下这一次save的结束时间。
这里有一个问题,在子进程保存期间,父进程的数据库已经被修改了,而父进程只是记录了修改的次数(dirty),被没有进行修正操作。似乎使得RDB保存的不是实时的数据库,有点不太高大上的样子。 不过后面要介绍的AOF持久化,就解决了这个问题。
除了客户执行sava或者bgsave命令,还可以配置RDB保存条件。即在配置文件中配置,在t时间内,数据库被修改了dirty次,则进行后台保存。redis在serve cron的时候,会根据dirty数目和上次保存的时间,来判断是否符合条件,符合条件的话,就进行bg save,注意,任意时刻只能有一个子进程来进行后台保存,因为保存是个很费io的操作,多个进程大量io效率不行,而且不好管理。
3.2 AOF持久化
RDB保存的只是最终的数据库,它是一个结果。
AOF不同不同RDB保存db的数据,它保存的是一条一条建立数据库的命令。
redis server中有一个sds aof_buf, 如果aof持久化打开的话,每个修改数据库的命令都会存入这个aof_buf(保存的是aof文件中命令格式的字符串),然后event loop每循环一次,在server cron中调用flushaofbuf,把aof_buf中的命令写入aof文件(其实是write,真正写入的是内核缓冲区),再清空aof_buf,进入下一次loop。这样所有的数据库的变化,都可以通过aof文件中的命令来还原,达到了保存数据库的效果。
如果不想使用aof_buf保存每次的修改命令,也可以使用aof持久化。redis提供aof_rewrite,即根据现有的数据库生成命令,然后把命令写入aof文件中。很奇特吧?对,就是这么厉害。进行aof_rewrite的时候,redis变量每个数据库,然后根据key-value对中value的具体类型,生成不同的命令,比如是list,则它生成一个保存list的命令,这个命令里包含了保存该list所需要的的数据,如果这个list数据过长,还会分成多条命令,先创建这个list,然后往list里面添加元素,总之,就是根据数据反向生成保存数据的命令。然后将这些命令存储aof文件,这样不就和aof append达到同样的效果了么?
aof格式也支持后台模式。执行aof_bgrewrite的时候,也是fork一个子进程,然后让子进程进行aof_rewrite,把它复制的数据库写入一个临时文件,然后写完后用新号通知父进程。父进程判断子进程的退出信息是否正确,然后将临时文件更名成最终的aof文件。
在子进程持久化期间,可能父进程的数据库有更新,怎么把这个更新通知子进程呢?难道要用进程间通信么?是不是有点麻烦呢?你猜redis怎么做的?它根本不通知子进程。什么,不通知?那更新怎么办? 在子进程执行aof_bgrewrite期间,父进程会保存所有对数据库有更改的操作的命令(增,删除,改等),把他们保存在aof_rewrite_buf_blocks中,这是一个链表,每个block都可以保存命令,存不下时,新申请block,然后放入链表后面即可,当子进程通知完成保存后,父进程将aof_rewrite_buf_blocks的命令append 进aof文件就可以了。
至于aof文件的载入,也就是一条一条的执行aof文件里面的命令而已。不过考虑到这些命令就是客户端发送给redis的命令,所以redis干脆生成了一个假的客户端,它没有和redis建立网络连接,而是直接执行命令即可。
4. redis的事务
redis另一个比memcached强大的地方,是它支持简单的事务。事务简单说就是把几个命令合并,一次性执行全部命令。对于关系型数据库来说,事务还有回滚机制,即事务命令要么全部执行成功,只要有一条失败就回滚,回到事务执行前的状态。redis不支持回滚,它的事务只保证命令依次被执行,即使中间一条命令出错也会继续往下执行,所以说它只支持简单的事务。
redis还提供了watch命令,用户可以在输入multi之前,执行watch命令,指定需要观察的数据,这样如果在exec之前,有其他的客户端修改了这些被watch的数据,则exec的时候,执行到处理被修改的数据的命令的时候,会执行失败,提示数据已经dirty。
redis的事务是简单的事务,算不上真正的事务,实际用处也不是太大。
5. redis的发布订阅频道
redis支持频道,即加入一个频道的用户相当于加入了一个群,客户往频道里面发的信息,频道里的所有client都能收到。
实现也很简单,也watch_keys实现差不多,redis server中保存了一个pubsub_channels的dict,里面的key是频道的名称(显然要唯一了),value则是一个链表,保存加入了该频道的client。同时,每个client都有一个pubsub_channels,保存了自己关注的频道。当用用户往频道发消息的时候,首先在server中的pubsub_channels找到改频道,然后遍历client,给他们发消息。而订阅,取消订阅频道不够都是操作pubsub_channels而已,很好理解。
同时,redis还支持模式频道。即通过正则匹配频道。
typedef struct pubsubPattern {
redisClient *client; // 监听的client
robj *pattern; // 模式
} pubsubPattern;
六、总结
总的来看,redis比memcached的功能多很多,实现也更复杂。 不过memcached更专注于保存key-value数据(这已经能满足大多数使用场景了),而redis提供更丰富的数据结构及其他的一些功能。不能说redis比memcached好,不过从源码阅读的角度来看,redis的价值或许更大一点。 另外,redis3.0里面支持了集群功能。