原文:http://blog.csdn.net/u013256816/article/details/52769297
数据库中间件
数据库相关平台主要解决以下三个方面的问题:
- 为海量前台数据提供高性能、大容量、高可用性的访问
- 为数据变更的消费提供准实时的保障
- 高效的异地数据同步
数据库中间件有以下几种:
- 分布式数据库分表分库
- 数据增量订阅与消费
- 数据库同步(全量、增量、跨机房、复制)
- 跨数据库(数据源)迁移
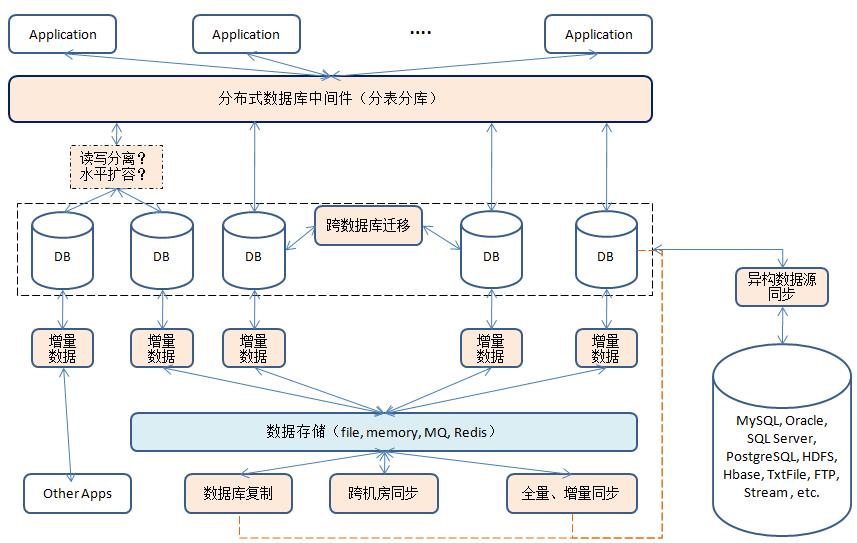
- 最上层的是分布式数据库分表分库中间件,负责和上层应用打交道,对应用可表现为一个独立的数据库,而屏蔽底层复杂的系统细节。分布式数据库中间件除了基本的分表分库功能,还可以丰富一下,比如讲读写分离或者水平扩容功能集成在一起,或者比如读写分离本身也可以作为一个独立的中间件。(Cobar, MyCAT, TDDL, DRDS, DDB)
- 增量数据订阅和消费,用户对数据库操作,比如DML, DCL, DDL等,这些操作会产生增量数据,下层应用可以通过监测这些增量数据进行相应的处理。典型代表Canal,根据MySQL的binlog实现。也有针对Oracle(redolog)的增量数据订阅与消费的中间件。(Canal, Erosa)
- 数据库同步中间件涉及数据库之间的同步操作,可以实现跨(同)机房同步以及异地容灾备份、分流等功能。可以涉及多种数据库,处理之后的数据也可以以多种形式存储。(Otter, JingoBus, DRC)
- 数据库与数据库之间会有数据迁移(同步)的动作,同款数据同步原理比较简单,比如MySQL主备同步,只要在数据库层进行相应的配置既可,但是跨数据库同步就比较复杂了,比如Oracle->MySQL。数据迁移一般包括三个步骤:全量复制,将原数据库的数据全量迁移到新数据库,在这迁移的过程中也会有新的数据产生;增量同步,对新产生的数据进行同步,并持续一段时间以保证数据同步;原库停写,切换新库。将“跨数据库”这个含义扩大一下——“跨数据源”,比如HDFS, HBase, FTP等都可以相互同步。(yugong, DataX)
分布式数据库
分表分库类的中间件主要有两种形式向应用提供服务:
- 一种是以JDBC的jar包形式为Java应用提供直接依赖,Java应用通过提供的JDBC包实现透明访问分布式数据库集群中的各个分库分表,典型代表网易的DDB和阿里的TDDL。
- 另一种是为应用部署独立的服务来满足应用分库分表的需求,在这种方式下通过标准JDBC访问Proxy,而Proxy则根据MySQL标准通信协议对客户端请求解析,还原应用SQL请求,然后通过本地访问数据库集群,最后再将得到的结果根据MySQL标准通信协议编码返回给客户端。典型代表阿里的Cobar, Cobar变种MyCAT, 阿里的DRDS,网易的DDB proxy模式以及DDB的私有云模式。
Cobar
Cobar 是提供关系型数据库(MySQL)分布式服务的中间件,它可以让传统的数据库得到良好的线性扩展,并看上去还是一个数据库,对应用保持透明。
Cobar以Proxy的形式位于前台应用和实际数据库之间,对前台的开放的接口是MySQL通信协议。将前台SQL语句变更并按照数据分布规则发到合适的后台数据分库,再合并返回结果,模拟单库下的数据库行为。
Cobar结构
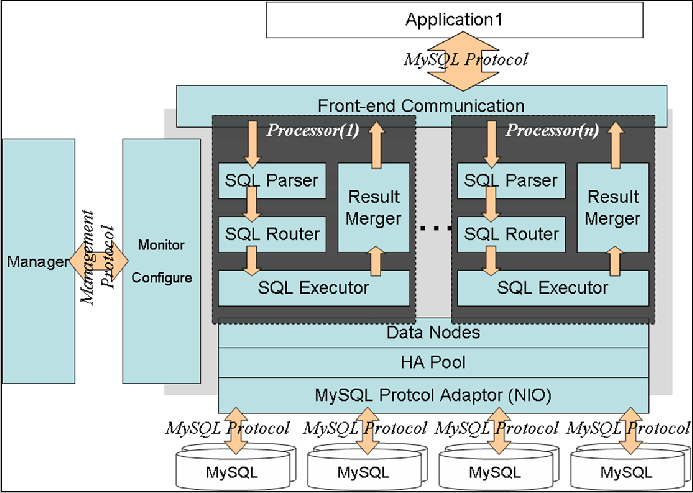
- 与应用之间通过MySQL protocol进行交互,是一个proxy的结构,对外暴露jdbc:mysql://CobarIP:port/schema。对应用透明。
- 无需引入新的jar包,从访问迁移到数据库访问Cobar可以复用原有的基于JDBC的DAO。
- Cobar前后端都实现了MySQL协议,当接受到SQL请求时,会一次进行解释(SQL Parser)和路由(SQL Router)工作,然后使用SQL Executor去后端模块获取数据集(后端模块还负责心跳检查功能);如果数据集来自多个数据源,Cobar则需要把数据集进行组合(Result Merge),最后返回响应。
- 数据库连接复用。Cobar使用连接池与后台真是数据库进行交互。(实际应用中,根据应用的不同,使用proxy结构后数据库连接数能够节约2-10倍不等。)
- Cobar事务,Cobar在单库的情况下保持事务的强一致性,分库的情况下保持事务的弱一致性,分库事务采用2PC协议,包括执行阶段和提交阶段
为了节省数据库的机器数量,可以采用下图中的方式部署:
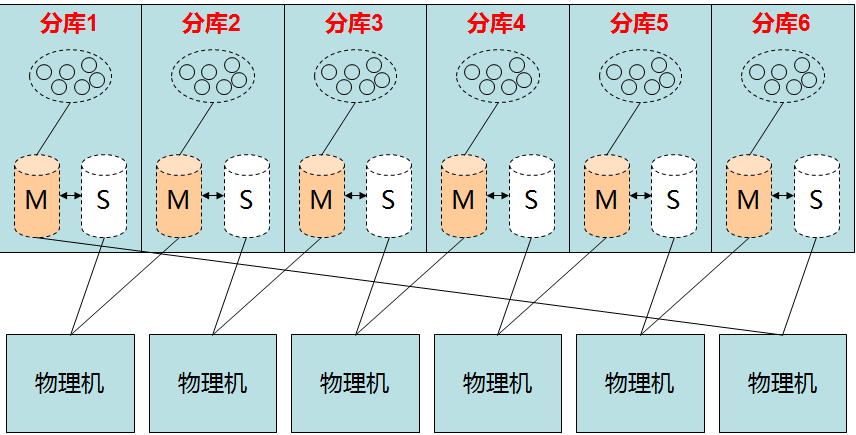
HA
在用户配置了MySQL心跳的情况下,Cobar可以自动向后端连接的MySQL发生心跳,判断MySQL运行状况,一旦运行出现异常,Cobar可以自动切换到备机工作。
Cobar解决的问题
分布式:Cobar的分布式主要是通过将表放入不同的库来实现。
- Cobar支持将一张表水平拆分成多份分别放入不同的库来实现表的水平拆分
- Cobar也支持将不同的表放入不同的库
- 多数情况下,用户将以上两种方式混合使用
需要强调的是,Cobar不支持将一张表,例如test表拆分成test_1, test_2, test_3….放在同一个库中,必须拆分后的表分别放入不同的库来实现分布式。
Cobar的约束
- 不支持跨库情况下的join、分页、排序、子查询操作
- SET语句执行会被忽略,事务和字符集设置除外
- 分库情况下,insert语句必须包括拆分字段列名
- 分库情况下,update语句不能更新拆分字段的值
- 不支持SAVEPOINT操作
- 暂时只支持MySQL数据节点
- 使用JDBC时,不支持rewriteBatchedStatements=true参数设置(默认为false)
- 使用JDBC时,不支持useServerPrepStmts=true参数设置(默认为false)
- 使用JDBC时,BLOB, BINARY, VARBINARY字段不能使用setBlob()或setBinaryStream()方法设置参数
MyCAT
从定义和分类看,它是一个开源的分布式数据库系统,是一个实现了MySQL协议的Server,前端用户可以把它看做是一个数据库代理,用MySQL客户端工具和命令行访问,而其后端可以用MySQL Native Protocol与多个MySQL服务器通信,也可以用JDBC协议与大多数主流数据库服务器通信,其核心功能是分表分库,即将一个大表水平分割为N个小表,存储在后端MySQL服务器里或者其他数据库里。
MyCAT发展到目前的版本,已经不是一个单纯的MySQL代理了,它的后端可以支持MySQL, SQL Server, Oracle, DB2, PostgreSQL等主流数据库,也支持MongoDB这种新型NoSQL方式的存储,未来还会支持更多类型的存储。
MyCAT是一个强大的数据库中间件,不仅仅可以用作读写分离,以及分表分库、容灾管理,而且可以用于多租户应用开发、云平台基础设施
MyCAT是在Cobar基础上发展的版本,两个显著提高:
- 后端由BIO改为NIO,并发量有大幅提高;
- 增加了对Order By, Group By, Limit等聚合功能(虽然Cobar也可以支持Order By, Group By, Limit语法,但是结果没有进行聚合,只是简单返回给前端,聚合功能还是需要业务系统自己完成)