
- 第1章 走入并行世界
- 第2章 Java并行程序基础
- 第3章 JDK并发包
- 4. 锁的优化及注意事项
- 第5章 并行模式与算法
第1章 走入并行世界
1.1 何去何从的并行计算
1.1.1 忘掉那该死的并行
并行计算只有在图像处理和服务器编程2个领域可以使用,并且它在这2个领域确实有着大量广泛的使用。
1.1.2 可怕的现实:摩尔定律的失效
摩尔定律在CPU的计算性能上可能已经失效。CPU主频的提升已经明显遇到了一些暂时不可逾越的瓶颈。
1.1.3 柳暗花明:不断地前进
多核CPU
1.1.4 光明或是黑暗
如何让多个CPU有效并且正确地工作也就成为了一门技术,甚至很大的学问。
1.2 你必须知道的几个概念
1.2.1 同步(Synchronous)和异步(Asynchronous)
同步和异步通常用来形容一次方法调用。
同步方法调用一旦开始,调用者必须等到方法调用返回后,才能继续后续行为。
异步方法调用更像一个消息传递,一旦开始,方法调用就会立即返回,调用者就可以继续后续的操作。而异步方法通常会在另外一个线程中”真实”地执行。
1.2.2 并发(Concurrency)和并行(Parallelism)
并发偏重于多个任务交替执行,而多个任务之间有可能还是串行的。而并行是真正意义上的同时执行。
1.2.3 临界区
临界区用来表示一种公共资源或者是共享数据,可以被多个线程使用。但是每一次,只能有一个线程使用它,一旦临界区资源被占用,其他线程要想使用这个资源,就必须等待。
在并行程序中,临界区资源是保护的对象。
1.2.4 阻塞(Blocking)和非阻塞(Non-Blocking)
阻塞和非阻塞通常用来形容多线程间的相互影响。
一个线程占用了临界区资源,那么其他所有需要这个资源的线程必须在这个临界区中进行等待。等待会导致线程挂起,这种情况就是阻塞。
非阻塞的意思与之相反,它强调没有一个线程可以妨碍其他线程执行。
1.2.5 死锁(Deadlock)、饥饿(Starvation)和活锁(Livelock)
死锁、饥饿和活锁都属于多线程的活跃性问题。如果发现上述几种情况,那么相关线程可能就不再活跃,也就说它可能很难再继续往下执行了。
死锁是最糟糕的一种情况。
饥饿是指某一个或者多个线程因为种种原因无法获得所需要的资源,导致一直无法执行。
如果线程的智力不够,且都秉承这谦让的原则,主动将资源释放给他人使用,那么就会出现资源不断在两个线程中跳动,而没有一个线程可以同时拿到所有资源而正常执行。这种情况就是活锁。
1.3 并发级别
由于临界区的存在,多线程之间的并发必须受到控制。根据控制并发的策略,我们可以把并发的级别进行分类,大致上可以分为阻塞、无饥饿、无障碍、无锁、无等待几种。
1.3.1 阻塞(Blocking)
一个线程是阻塞的,那么在其他线程释放资源之前,当前线程无法继续执行。当我们使用synchronized关键字,或者重入锁时,我们得到的就是阻塞的线程。
无论是synchronized或者重入锁,都会试图在执行后续代码前,得到临界区的锁,如果得不到,线程就会被挂起等待,直到占有了所需资源为止。
1.3.2 无饥饿(Starvation-Free)
对于非公平的锁来说,系统允许高优先级的线程插队。这样有可能导致低优先级线程产生饥饿。
如果锁是公平的,满足先来后到,那么饥饿就不会产生。
1.3.3 无障碍(Obstruction-Free)
无障碍是一种最弱的非阻塞调度。两个线程如果是无障碍的执行,那么他们不会因为临界区的问题导致一方被挂起。一旦检测到大家一起修改共享数据,它就立即对自己所做的修改进行回滚,确保数据安全。但如果没有数据竞争发生,那么线程就可以顺利完成自己的工作,走出临界区。
一种可行的无障碍实现可以依赖一个一致性标记来实现。线程在操作之前,先读取并保存这个标记,在操作完成后,再次读取,检查这个标记是否被更改过,如果两者是一致的,则说明资源访问没有冲突。如果不一致,则说明资源可能在操作过程中与其他写线程冲突,需要重试操作。
1.3.4 无锁(Lock-Free)
无锁的并行都是无障碍的。在无锁的情况下,所有的线程都能尝试对临界区进行访问,但不同的是,无锁的并发保证必然有一个线程能够在有限步内完成操作离开临界区。
无锁的示意代码:
while (!atomicVar.compareAndSet(localVar, localVar + 1)) {
localVar = atomicaVar.get();
}
1.3.5 无等待(Wait-Free)
无锁只要求有一个线程可以在有限步内完成操作,而无等待则在无锁的基础上更进一步进行扩展。它要求所有的线程都必须在有限步内完成,这样就不会引起饥饿问题。
一种典型的无等待结构就是RCU(Read-Copy-Upate)。它的基本思想是,对数据的读可以不加控制。因此,所有的读线程都是无等待的,它们既不会被锁定等待也不会引起任何冲突。但在写数据的时候,先取得原始数据的副本,接着只修改副本数据(这就是为什么读可以不加控制),修改完成后,在合适的时机回写数据。
1.4 有关并行的两个重要定律
使用并行程序的两个目的:
- 第一,为了获取更好的性能;
- 第二,由于业务模型的需要,确实需要多个执行实体。
1.4.1 Amdahl定律
加速比定义:加速比 = 优化前系统耗时 / 优化后系统耗时。加速比越高,表明优化效果越明显。
根据Amdahl定律,使用多核CPU对系统进行优化,优化的效果取决于CPU的数量以及系统中的串行化程序的比重。CPU数量越多,串行化比重越低,则优化效果越好。仅提高CPU数量而不降低程序的串行化比重,也无法提高系统性能。
1.4.2 Gustafson定律
从Gustafson定律中,我们可以更容易地发现,如果串行化比例很小,并行化比例很大,那么加速比就是处理器的个数。只要你不断地累加处理器,就能获得更快的速度。
1.4.3 Amdahl定律和Gustafson定律是否相互矛盾
这两个定律并不矛盾。从极端角度来说,如果系统中没有可被并行化的代码(即F=1),那么对于这两个定律,其加速比都是1。反之,如果系统中可并行化代码比重达到100%,那么这两个定律得到的加速比都是n(处理器个数)。
1.5 回到Java:JMM
Java内存模型
JMM的关键技术点都是围绕着多线程的原子性、可见性和有序性来建立的。
1.5.1 原子性(Atomicity)
原子性是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
对于32位系统来说,long型数据的读写不是原子性的。如果两个线程同时对long进行写入的话(或者读取),对线程之间的结果是有干扰的。
1.5.2 可见性(Visibility)
可见性是指当一个线程修改了某一个共享变量的值,其他线程是否能够立即知道这个修改。
除了缓存优化或者硬件优化会导致可见性问题外,指令重排以及编译器的优化,都有可能导致一个线程的修改不会立即被其他线程察觉。
1.5.3 有序性(Ordering)
有序性问题的原因是因为程序在执行时,可能会进行指令重排,重排后的指令与原指令的顺序未必一致。
指令重排可以保证串行语义一致,但是没有义务保证多线程间的语义也一致。
ALU指算数逻辑单元。它是CPU的执行单元,是CPU的核心组成部分,主要功能是进行二进制算术运算。
之所以需要做指令重排,就是为了尽量少的中断流水线。
指令重排对于提高CPU处理性能是十分必要的。
1.5.4 哪些指令不能重排:Happen-Before规则
以下基本原则是指令重排不可违背的:
- 程序顺序原则:一个线程内保证语义的串行性。
- volatile规则:对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。这保证了volatile变量的可见性。
- 锁规则:如果对一个锁解锁后,再加锁,那么加锁的动作绝对不能重排到解锁动作之前。
- 传递性:A先于B,B先于C,那么A必然先于C。
- 线程的start()方法先于它的每一个动作。
- 线程的所有操作先于线程的终结(Thread.join())。
- 线程的中断(interrupt())先于被中断线程的代码(不运行中断之后的代码)。
- 对象的构造函数执行、结束先于finalize()方法。
1.6 参考文献
第2章 Java并行程序基础
2.1 有关线程你必须知道的事
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统机构的基础。
线程是轻量级进程,是程序执行的最小单位。使用多线程而不是用多进程去进行并发程序的设计,是因为线程间的切换和调度的成本远远小于进程。
线程状态图:
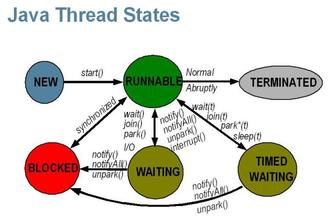
- NEW状态表示刚刚创建的线程,这种线程还没开始执行。
- 等到线程的start()方法调用时,才表示线程开始执行。当线程执行时,处于RUNNABLE状态,表示线程所需的一切资源都已经准备好了。
- 如果线程在执行过程中遇到了synchronized同步块,就会进入BLOCKED阻塞状态,这时线程就会暂停执行,直到获得请求的锁。
- WAITING和TIMED_WAITING都表示等待状态,它们的区别是WAITING会进入一个无时间限制的等待,TIMED_WAITING会进行一个有时限的等待。一旦等到了期望的事件,线程就会再次执行,进入RUNNABLE状态。
- 当线程完毕后,则进入TERMINATED状态,表示结束。
2.2 初始线程:线程的基本操作
2.2.1 新建线程
Thread t1 = new Thread();
t1.start();
start()方法会新建一个线程并让这个线程执行run()方法。
不要用run()来开启新线程。它只会在当前线程中,串行执行run()中的代码。
实现Runnable接口,并将该实例传入Thread。这样避免重载Thread.run(),单纯使用接口来定义Thread,也是最常用的做法。
public class MyThread implements Runnable {
public static void main(String[] args) {
Thread t1 = new Thread(new MyThread());
t.start();
}
@Override
public void run() {
...
}
}
2.2.2 终止线程
Thread.stop()方法在结束线程时,会直接终止线程,并且会立即释放这个线程所持有的锁。而这些锁恰恰是用来维持对象一致性的。如果此时,写线程写入数据正写到一半,并强行终止,那么对象就会被写坏,同时,由于锁已经被释放,另外一个等待该锁的读线程就顺理成章的读到了这个不一致的对象,悲剧也就此发生。
除非你很清楚你在做什么,否则不要随便使用stop()方法来停止一个线程。
如果需要停止一个线程时,只需要我们自行决定线程何时退出就可以了,例如:
public static class ChangeObjectThread extends Thread {
volatile boolean stopme = false;
public void stopMe() {
stopme = true;
}
@Override
public void run() {
while(true) {
if (stopme) {
break;
}
...
}
}
}
2.2.3 线程中断
线程中断并不会使线程立即退出,而是给线程发送一个通知,告知目标线程,有人希望你退出啦!至于目标线程接到通知后如何处理,则完全由目标线程自行决定。
public void Thread.interrupt() // 中断线程
public boolean Thread.isInterrupted() // 判断是否被中断
public static boolean Thread.interrupted() // 判断是否被中断,并清除当前中断状态
Thread.sleep()方法会让当前线程休眠若干时间,它会抛出一个InterruptedException中断异常,当线程在sleep休眠时,如果被中断,这个异常就会产生。
Thread t1 = new Thread() {
@Override
public void run() {
while (true) {
if (Thread.currentThread().isInterrupted()) {
System.out.println("Interrupted!");
break;
}
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
System.out.println("Interrupted When Sleep");
// 设置总断状态
Thread.currentThread().interrupt();
}
Thread.yield();
}
}
};
t1.start();
Thread.sleep(2000);
t1.interrupt();
Thread.sleep()方法由于中断而抛出异常,此时,它会清除中断标记,如果不加处理,那么在下一次循环开始时,就无法捕获这个中断,故在异常处理中,再次设置中断标记位。
2.2.4 等待(wait)和通知(notify)
Object类中有两个非常重要的接口线程:
public final void wait() throws InterruptedException
public final native void notify()
线程A中,调用了obj.wait()方法,那么线程A就会停止继续执行,而转为等待状态。线程A会一直等到其他线程调用了obj.notify()方法为止。这时,obj对象就俨然成为多个线程之间的有效通信手段。
如果一个线程调用了object.wait(),那么它就会进入object对象的等待队列。这个等待队列中,可能会有多个线程,因为系统运行多个线程同时等待某一个对象。当object.notify()被调用时,它就会从这个等待队列中,随机选择一个线程,并将其唤醒。这个选择是不公平的,并不是先等待的线程会优先被选择,这个选择完全是随机的。
除了notify()方法外,Object对象还有一个类似的notifyAll()方法,它和notify()的功能基本一致,但不同的是,它会唤醒在这个等待队列中所有等待的线程,而不是随机选择一个。
Object.wait()方法并不是可以随便调用的。它必须包含在对应的synchronzied语句中,无论是wait()或者notify()都需要首先获得目标对象的一个监视器。
wait()方法执行前,首先必须获得object对象的监视器。而wait()方法执行后,会释放这个监视器。这样做的目的是使得其他等待在object对象上的线程不至于因为该线程的休眠而全部无法正常执行。
notify()调用前,也必须获得object的监视器,此时需要其他线程已经释放了该监视器。执行了notify()方法后会尝试唤醒一个等待线程。被唤醒的线程要做的第一件事并不是执行后续的代码,而是要尝试重新获得object的监视器,如果无法获得,则还必须等待这个监视器。当监视器顺利获得后,被唤醒的线程才可以真正意义上的继续执行。
Object.wait()和Thread.sleep()方法都可以让线程等待若干时间。除了wait()可以被唤醒外,另外一个主要区别就是wait()方法会释放目标对象的锁,而Thread.sleep()方法不会释放任何资源。
notify()和notifyAll()都是Object对象用于通知处在等待对象的线程的方法。两者的最大区别在于:
- notifyAll使所有原来在该对象上等待被notify的线程统统退出wait的状态,变成等待该对象上的锁,一旦该对象被解锁,他们就会去竞争。
- notify只选择一个wait状态线程进行通知,并使它获得该对象上的锁,但不惊动其他同样在等待被该对象notify的线程们。当第一个线程运行完毕以后释放对象上的锁此时如果该对象没有再次使用notify语句,则即便该对象已经空闲,其他wait状态等待的线程由于没有得到该对象的通知,继续处在wait状态,直到这个对象发出一个notify或notifyAll,它们等待的是被notify或notifyAll,而不是锁。
2.2.5 挂起(suspend)和继续执行(resume)线程
这两个操作是一对相反的操作,被挂起的线程,必须要等到resume()操作后,才能继续执行。它们是早已被标注为废弃方法。
不推荐使用suspend()去挂起线程的原因,是因为suspend()在导致线程暂停的同时,并不会去释放任何锁资源。此时,其他任何线程想要访问被它暂用的锁时,都会被牵连,导致无法正常继续运行。直到对应的线程进行了resume()操作,被挂起的线程才能继续,从而其他所有阻塞在相关锁上的线程也可以继续执行。
一个利用wait()和notify()方法,在应用层面实现suspend()和resume()功能的例子:
public static class ChangeObjectThread extends Thread {
volatile boolean suspendme = false;
public void suspendMe() {
suspendme = true;
}
public void resumeMe() {
suspendme = false;
synchronized(this) {
notify();
}
}
@Override
public void run() {
while (true) {
synchronized(this) {
while(suspendMe) {
try {
wait();
} catch (InterruptedException e) {
...
}
}
}
}
...
}
}
2.2.6 等待线程结束(join)和谦让(yield)
JDK提供了以下2个join()方法:
public final void join() throws InterruptedException
public final synchronized void join(long mills) throws InterruptedException
第一个join()方法表示无限等待,它会一直阻塞当前线程,直到目标线程执行完毕。
第二个方法给出了一个最大等待时间,如果超过给定时间目标线程还在执行,当前线程也会因为等不及了,而继续往下执行。
另一个比较有趣的方法,Thread.yield(),定义如下:
public static native void yield();
这是一个静态方法,一旦执行,它会使当前线程让出CPU。但这并不表示当前线程不执行了,它还会进行CPU资源的争夺,但是是否能够再次被分配到,就不一定了。
如果觉得一个线程不那么重要,或者优先级非常低,而且又害怕它会占用太多的CPU资源,那么可以在适当的时候调用Thread.yield(),给予其他重要线程更多的工作机会。
2.3 volatile与Java内存模型(JMM)
用volatile去申明一个变量时,就等于告诉了虚拟机,这个变量极有可能会被某些程序或者线程修改。为了确保这个变量被修改后,应用程序范围内的所有线程都能够看到这个改动,虚拟机就必须采用一些特殊的手段,保证这个变量的可见性等特点。
volatile对于保证操作的原子性有非常大的帮助,但volatile并不能代替锁,它也无法保证一些复合操作的原子性。
volatile也能保证数据的可见性和有序性。
可以使用Java虚拟机参数-server切换到Server模式。
2.4 分门别类的管理:线程组
ThreadGroup:线程组,两个重要的功能:
- activeCount()可以获得活动线程的总数,但由于线程是动态的,因此这个值只是一个估计值,无法确定精确。
- list()方法可以打印这个线程组中所有的线程信息,对调试有一定帮助。
线程租还有一个方法stop(),它会停止线程组中所有的线程,但它会遇到和Thread.stop()相同的问题,因此慎用。
2.5 驻守后台:守护线程(Daemon)
守护线程是一种特殊的线程,它是系统的守护者,在后台默默地完成一些系统性的服务,比如垃圾回收线程、JIT线程就可以理解为守护线程。与之相对应的是用户线程,用户线程可以认为是系统的工作线程。
守护线程要守护的对象已经不存在了,那么整个应用程序就自然应该结束。因此,当一个Java应用内,只有守护线程时,Java虚拟机就会自然退出。
设置守护线程必须在线程start之前设置,设置方法为setDaemon(true)。
2.6 先干重要的事:线程优先级
Java中的线程可以有自己的优先级。优先级高的线程在竞争资源时会更有优势,更可能抢占资源,当然,这只是一个概率问题。
在Java中,使用1到10表示线程优先级。
方法:setPriority()
2.7 线程安全的概念与synchronized
volatile并不能真正的保证线程安全。它只能确保一个线程修改了数据后,其他线程能看到这个改动。但当两个线程同时修改某一个数据时,却依然会产生冲突。
关键字synchronized的作用是实现线程间的同步。它的工作是对同步的代码加锁,使得每一次,只能有一个线程进入同步块,从而保证线程间的安全性。
关键字synchronized可以有多种用法:
- 指定加锁对象:对给定对象加锁,进入同步代码前要获得给定对象的锁。
- 直接作用于实例方法:相当于对当前实例加锁,进入同步代码前要获得当前实例的锁。
- 直接作用于静态方法:相当于对当前类加锁,进入同步代码前要获得当前类的锁。
除了用于线程同步、确保线程安全外,synchronized还可以保证线程间的可见性和有序性。
2.8 程序中的幽灵:隐蔽的错误
2.8.1 无提示的错误案例
2.8.2 并发下的ArrayList
ArrayList是一个线程不安全的容器,如果在多线程中使用ArrayList,可能会导致程序出错。
改进的方法:使用线程安全的Vector代替ArrayList即可。
2.8.3 并发下诡异的HashMap
HashMap同样不是线程安全的。当你使用多线程访问HashMap时,也可能会遇到意想不到的错误。可能程序永远无法结束。
最简单的解决方案:使用ConcurrentHashMap代替HashMap。
2.8.4 初学者常见问题:错误的加锁
在Java中,Integer属于不变对象,也就是对象一旦被创建,就不可能被修改。
2.9 参考文献
第3章 JDK并发包
3.1 多线程的团队协作:同步控制
3.1.1 synchronized的功能扩展:重入锁
重入锁可以完全替代synchronized关键字。在JDK 5.0的早期版本中,重入锁的性能远远好于synchronized,但从JDK 6.0开始,JDK在synchronized上做了大量的优化,使得两者的性能差距并不大。
public class ReenterLock implements Runnable {
public static ReentrantLock lock = new ReentrantLock();
public static int i = 0;
@Override
public void run() {
for (int j = 0; j < 10000000; j++) {
lock.lock();
try {
i++;
} finally {
lock.unlock();
}
}
}
public static void main(String[] args) throws InterruptedException {
ReenterLock tl = new ReenteerLock();
Thread t1 = new Thread(tl);
Thread t2 = new Thread(tl);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(i);
}
}
与synchonized相比,重入锁有着显示的操作过程。开发人员必须手动指定何时加锁,何时释放锁。
重入锁是可以反复进入的:
lock.lock();
lock.lock();
try {
i++;
} finally {
lock.unlock();
lock.unlock();
}
中断响应
对于synchronized来说,如果一个线程在等待锁,那么结果只有两种情况,要么它获得这把锁继续执行,要么它就保持等待。而使用重入锁,则提供另外一种可能,那就是线程可以被中断。也就是在等待锁的过程中,程序可以根据需要取消对锁的请求。
lock.lockInterrupibly();
对锁的请求,统一使用上述方法,这是一个可以对中断进行响应的锁申请动作,即在等待锁的过程中,可以响应中断。
锁申请等待限时
除了等待外部通知之外,要避免死锁还有另外一种方法,那就是限时等待。
可以使用tryLock()方法进行一次限时的等待
lock.tryLock(5, TimeUnit.SECONDS);
ReentrantLock.tryLock()方法也可以不带参数直接运行。在这种情况下,当前线程会尝试获得锁,如果锁并未被其他线程占用,则申请锁会成功,并立即返回true。如果锁被其他线程占用,则当前线程不会进行等待,而是立即返回false。
公平锁
我们使用synchronized关键字进行锁控制,那么产生的锁就是非公平的。而重入锁允许我们对其公平性进行设置。它有一个如下的构造函数:
public ReentrantLock(boolean fair)
公平锁看起来很优美,但是要实现公平锁必然要求系统维护一个有序队列,因此公平锁的实现成本比较高,性能相对也非常低下,因此,默认情况下,锁是非公平的。
ReentrantLock的几个重要方法如下:
- lock():获得锁,如果锁已经被占用,则等待。
- lockInterruptibly():获得锁,但优先响应中断。
- tryLock():尝试获得锁,如果成功,返回true,失败返回false。该方法不等待,立即返回。
- tryLock(long time, TimeUnit unit):在给定时间内尝试获得锁。
- unlock():释放锁。
在重入锁的实现中,主要包含三个要素:
- 第一,是原子状态。原子状态使用CAS操作来存储当前锁的状态,判断锁是否已经被别的线程持有。
- 第二,是等待队列。
- 第三,是阻塞原语park()和unpark(),用来挂起和恢复线程。没有得到锁的线程将会被挂起。
3.1.2 重入锁的好搭档:Condition条件
通过Lock接口(重入锁就实现了这一接口)的Condition newCondition()方法可以生成一个与当前重入锁绑定的Condition实例。利用Condition对象,我们就可以让线程在合适的时间等待,或者在某一个特定的时间得到通知,继续执行。
3.1.3 允许多个线程同时访问:信号量(Semaphore)
信号量为多线程协作提供了更为强大的控制方法。广义上说,信号量是对锁的扩展,无论是内部锁synchronized还是重入锁ReentrantLock,一次都只允许一个线程访问一个资源,而信号量却可以指定多个线程,同时访问某一个资源。信号量主要提供了以下构造函数:
public Semaphore(int permits)
public Semaphore(int permits, boolean fair) // 第二个参数可以指定是否公平
信号量的主要逻辑方法有:
- acquire()方法尝试获得一个准入的许可,若无法获得,则线程会等待,直到有线程释放一个许可或者当前线程被中断。
- acquireUninterruptibly()方法和acquire()方法类似,但是不响应中断。
- tryAcquire()尝试获得一个许可,如果成功返回true,失败则返回false,它不会进行等待,立即返回。
- release()用于在线程访问资源结束后,释放一个许可,以使其他等待许可的线程可以进行资源访问。
3.1.4 ReadWriteLock 读写锁
读写分离锁可以有效地帮助减少锁竞争,以提升系统性能。
- 读-读不互斥:读读之间不阻塞。
- 读-写互斥:读阻塞写,写也会阻塞读。
- 写-写互斥:写写阻塞。
如果在系统中,读操作次数远远大于写操作,则读写锁就可以发挥最大的功效,提升系统的性能。
3.1.5 倒计时器:CountDownLatch
CountDownLatch是一个非常实用的多线程控制工具类。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
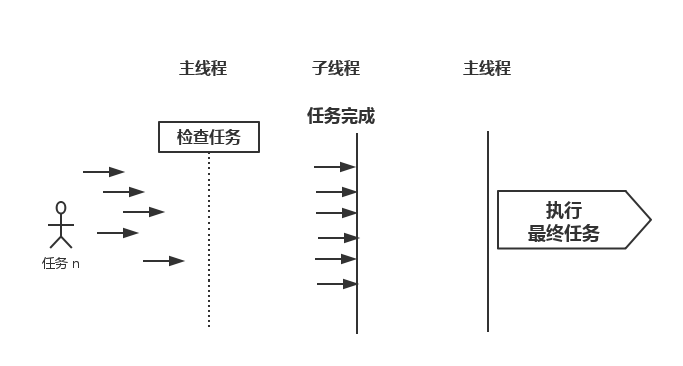
主线程在CountDownLatch上等待,当所有检查任务全部完成后,主线程方能继续执行。
3.1.6 循环栅栏:CyclicBarrier
CyclicBarrier是另外一种多线程并发控制实用工具。和CountDownLatch非常类似,它也可以实现线程间的计数等待,但它的功能比CountDownLatch更加复杂且强大。
CyclicBarrier计数器可以反复使用。
比CountDownLatch略微强大一些,CyclicBarrier可以接收一个参数作为barrierAction。
CyclicBarrier.await()方法可能会抛出两个异常:
- InterruptedException:在等待过程中,线程被中断,应该说这是一个非常通用的异常。
- BrokenBarrierException:这是CyclicBarrier特有的异常,一旦遇到这个异常,则表示当前的CyclicBarrier已经破损了,可能系统已经没有办法等待所有线程到齐了。
3.1.7 线程阻塞工具类:LockSupport
LockSupport是一个非常方便实用的线程阻塞工具,它可以在线程内任意位置让线程阻塞。和Thread.suspend()相比,它弥补了由于resume()在前发生,导致线程无法继续执行的情况。和Object.wait()相比,它不需要先获得某个对象的锁,也不会抛出InterruptedException异常。
LockSupport的静态方法park()可以阻塞当前线程,类似的还有parkNanos()、parkUnit()等方法。它们实现了一个限时的等待。
LockSupport类使用类似信号量的机制。它为每一个线程准备了一个许可,如果许可可用,那么park()函数会立即返回,并且消费这个许可(也就是将许可变为不可用),如果许可不可用,就会阻塞。而unpack()则使得一个许可变为可用(但是和信号量不同是,许可不能累加,你不可能拥有超过一个许可,它永远只有一个)。
这个特点使得,即使unpark()操作发生在park()之前,它也可以使下一次的park()操作立即返回。
处于park()挂起状态的线程不会像suspend()那样还给出一个令人费解的Runnable的状态。它会非常明确地给出一个WAITING状态,甚至还会标注是park()引起的。
如果你使用park(Object)函数,还可以为当前线程设置一个阻塞对象,这个阻塞对象会出现在线程Dump中。
除了有定时阻塞的功能外,LockSupport.park()还能支持中断影响。但是和其他接收中断的函数很不一样,LockSupport.park()不会抛出InterruptedException异常。它只会默默的返回。但是我们可以从Thread.interrupted()等方法获得中断标记。
3.2 线程复用:线程池
若不加控制和管理的随意使用线程,对系统的性能反而会产生不利的影响。
在实际生产环境中,线程的数量必须得到控制。盲目的大量创建线程对系统性能是有伤害的。
3.2.1 什么是线程池
3.2.2 不要重复发明轮子:JKD对线程池的支持
Executor框架提供了各种类型的线程池:
- newFixedThreadPool()方法:该方法返回一个固定线程数量的线程池。
- newSingleThreadExecutor()方法:该方法返回一个只有一个线程的线程池。
- newCachedThreadPool()方法:该方法返回一个可根据实际情况调整线程数量的线程池。
- newSingleThreadScheduledExecutor()方法:该方法返回一个scheduledExecutorService对象,线程池大小为1。ScheduledExecutorService接口在ExecutorService接口之上扩展了在给定时间执行某任务的功能,如在某个固定的延时之后执行,或者周期性执行某个任务。
- newScheduledThreadPool()方法:该方法也返回一个ScheduledExecutorService对象,但该线程池可以指定线程数量。
3.2.3 刨根究底:核心线程池的内部实现
线程池的实现都是ThreadPoolExecutor类的封装
ThreadPoolExecutor最重要构造函数的参数含义:
- corePoolSize:指定了线程池中的线程数量
- maximumPoolSize:指定了线程池中的最大线程数量
- keepAliveTime:当线程池数量超过corePoolSize时,多余的空闲线程的存活时间。即,超过corePoolSize的空闲线程,在多长时间内,会被销毁。
- unit:keepAliveTime的单位。
- workQueue:任务队列,被提交但尚未被执行的任务。
- threadFactory:线程工厂,用于创建线程,一般用默认的即可。
- handler:拒绝策略。当任务太多来不及处理,如何拒绝任务。
对于newCachedThreadPool(),如果同时有大量任务被提交,而任务的执行又不那么快时,那么系统便会开启等量的线程处理,这样做法可能会很快耗尽系统的资源。
注意:使用自定义线程池时,要根据应用的具体情况,选择合适的并发队列作为任务的缓冲。当线程资源紧张时,不同的并发队列对系统行为和性能的影响均不同。
3.2.4 超负载了怎么办:拒绝策略
JDK内置的拒绝策略:
- AbortPolicy策略:该策略会直接抛出异常,阻止系统正常工作。
- CallerRunsPolicy策略:只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务。显然这样做不会真的丢弃任务,但是,任务提交线程的性能极有可能会急剧下降。
- DiscardOledestPolicy策略:该策略将丢弃最老的一个请求,也就是即将被执行的一个任务,并尝试再次提交当前任务。
- DiscardPolicy策略:该策略默默地丢弃无法处理的任务,不予任务处理。
自己扩展RejectedExecutionHandler接口:
publi interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
其中r为请求执行的任务,executor为当前的线程池。
3.2.5 自定义线程创建:ThreadFactory
ThreadFactory是一个接口,它只有一个方法,用来创建线程:
Thread newThread(Runnable r);
3.2.6 我的应用我做主:扩展线程池
ThreadPoolExecutor是一个可以扩展的线程池。它提供了beforeExecute()、afterExecute()和terminated()三个接口对线程池进行控制。
3.2.7 合理的选择:优化线程池线程数量
为保持处理器达到期望的使用率,最优的池的大小等于:
Nthreads = Ncpu * Ucpu * (1 + W/C)
- Ncpu = CPU的数量
- Ucpu = 目标CPU的使用率,[0, 1]之间
- W/C = 等待时间与计算时间的比率
在Java中,可以通过:
Runtime.getRuntime().availableProcessors()
取得可用的CPU数量。
3.2.8 堆栈去哪里了:在线程池中寻找堆栈
放弃submit,改用execute():
pools.execute(new DivTask(100, i));
或者使用下面的方法改造submit():
Future re = pools.submit(new DivTask(100, i));
re.get();
上面两种方法都可以得到部分堆栈信息。
最终解决方案:自定义扩展ThreadPoolExecutor线程池,让它在调度任务之前,先保存一下提交任务线程的堆栈信息。
public class TraceThreadPoolExecutor extends ThreadPoolExecutor {
public TraceThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
public void execute(Runnable task) {
super.execute(wrap(task, clientTrace(), Thread.currentThread().getName()));
}
@Override
public Future<?> submit(Runnable task) {
return super.submit(wrap(task, clientTrace(), Thread.currentThread().getName()));
}
private Exception clientTrace() {
return new Exception("Client stack trace");
}
private Runnable wrap(final Runnable task, final Exception clientStack, String currentThreadName) {
return new Runnable() {
@Override
public void run() {
try {
task.run();
} catch (Exception e) {
clientStack.printStackTrace();
throw e;
}
}
}
}
}
3.2.9 分而治之:Fork/Join框架
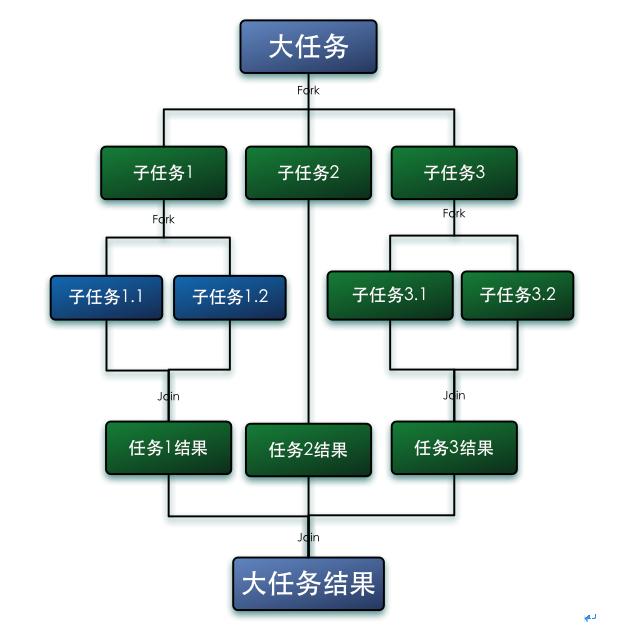
ForkJoinPool的一个重要的接口:
public <T> ForkJoinTak<T> submit(ForkJoinTask<T> task)
你可以向ForkJoinPool线程池提交一个ForkJoinTask任务。所谓ForkJoinTask任务就是支持fork()分解以及join()等待的任务。ForkJoinTask有两个重要的子类,RecursiveAction和RecursiveTask。它们分别表示没有返回值的任务和可以携带返回值的任务。
public class CountTask extends RecursiveTask<Long> {
private static final int THRESHOLD = 10000;
private long start;
private long end;
public CountTask(long start, long end) {
this.start = start;
this.end = end;
}
public Long compute() {
long sum = 0;
boolean canCompute = (end - start) < THRESHOLD;
if (canCompute) {
for (long i = start; i <= end; i++) {
sum += i;
}
} else {
// 分成100个小任务
long step = (start + end) / 100;
ArrayList<CountTask> subTasks = new ArrayList<CountTask>();
long pos = start;
for (int i = 0; i < 100; i ++) {
long lastOne = pos + step;
if (lastOne > end) {
lastOne = end;
}
CountTask subTask = new CountTask(pos, lastOne);
pos += step + 1;
subTasks.add(subTask);
subTask.fork();
}
for (CountTask t : subTasks) {
sum += t.join();
}
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
CountTask task = new CountTask(0, 200000L);
ForkJoinTask<Long> result = forkJoinPool.submit(task);
try {
long res = result.get();
System.out.println("sum=" + res);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
在使用ForkJoin时需要注意,如果任务的划分层次很深,一直得不到返回,那么可能出现两种情况:
- 第一,系统内的线程数量越积越多,导致性能严重下降。
- 第二,函数的调用层次变得很深,最终导致栈溢出。
ForkJoin线程池使用一个无锁的栈来管理空闲线程。如果一个工作线程暂时取不到可用的任务,则可能会被挂起,挂起的线程将会被压入由线程池维护的栈中。待将来有任务可用时,再从栈中唤醒这些线程。
3.3 不要重复发明轮子:JDK的并发容器
3.3.1 超好用的工具类:并发集合简介
这些容器大部分在java.util.concurrent包中
- ConcurrentHashMap:高效的、线程安全的HashMap
- CopyOnWriteArrayList:和ArrayList一族,在读多写少的场合,这个List的性能非常好,远远好于Vector。
- ConcurrentLinkedQueue:高效的并发队列,使用链表实现。可以看做是一个线程安全的LinkedList。
- BlockingQueue:这是一个接口,JDK内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。
- ConcurrentSkipListMap:跳表的实现。这是一个Map,使用跳表的数据结构进行快速查找。
除了以上并发包中的专有数据结构外,java.util下的Vecotor是线程安全的(虽然性能和上述专用工具没得比),另外Collections工具类可以帮助我们将任意集合包装成线程安全的集合。
3.3.2 线程安全的HashMap
一种可行的方法是使用Collections.synchronizedMap()方法包装我们的HashMap。如下代码,产生的HashMap就是线程安全的:
public static Map m = Collections.synchronizedMap(new HashMap());
Collections.synchronizedMap()会生成一个名为SynchronizedMap的Map。它使用委托,将自己所有Map相关的功能交给传入的HashMap实现,而自己则主要负责保证线程安全。这个包装的Map可以满足线程安全的要求,但是,它在多线程环境中的性能表现并不算太好。
一个更加专业的并发HashMap是ConcurrentHashMap。它位于java.util.concurrent包内。它专门为并发进行了性能优化,因此,更加适合多线程的场合。
3.3.3 有关List的线程安全
public static List<String> l = Collctions.synchronizedList(new LinkedList<String>());
3.3.4 高效读写的队列:深度剖析ConcurrentLinkedQueue
节点Node核心:
private static class Node<E> {
volatile E item;
volatile Node<E> next;
}
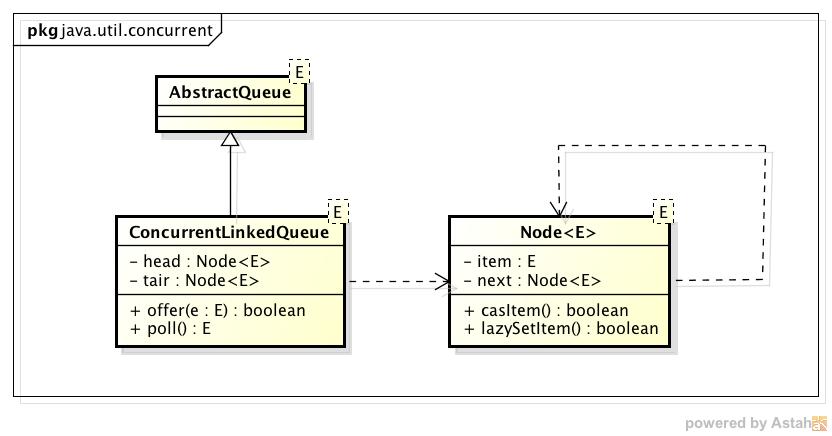
对Node进行操作时,使用了CAS操作。
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwap(this, itemOffset, cmp, val);
}
boolean lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);
}
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.cmpareAndSwapObject(this, nextOffset, cmp, val);
}
方法casItem()表示设置当前Node的item值。它需要两个参数,第一个参数为期望值,第二个参数为设置目标值。当当前值等于cmp期望值时,就会将目标设置为val。同样casNext方法也是类似的,但是它是用来设置next字段,而不是item字段。
ConcurrentLinkedQueue的内部实现非常复杂,它允许在运行时链表处于多个不同的状态。如tail的更新并不是及时的。
不使用锁而单纯地使用CAS操作会要求在应用层面保证线程安全,并处理一些可能存在的不一致问题,大大增加了程序设计和实现的难度。但是它带来的好处就是可以得到性能的飞速提升。
3.3.5 高效读取:不变模式下的CopyOnWriteArrayList
所谓CopyOnWrite就是在写入操作时,进行一次自我复制。
3.3.6 数据共享通道:BlockingQueue
BlockingQueue是一个接口,并非一个具体的实现,主要实现有:ArrayBlockingQueue和LinkedBlockingQueue。
BlockingQueue很好地解决了这个问题,它会让服务线程在队列为空时,进行等待,当有新的消息进入队列后,自动将线程唤醒。
3.3.7 随机数据结构:跳表(SkipList)
跳表是一种可以用来快速查找的数据结构,有点类似于平衡树。
重要区别:对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整,而对跳表的插入和删除只需要对整个数据结构的局部进行操作即可。
好处:在高并发情况下,你会需要一个全局锁来保证整个平衡树的线程安全。而对于跳表,你只需要部分锁即可。这样,在高并发环境下,你就可以拥有更好的性能。
跳表是一种使用空间换时间的算法。
使用跳表实现Map和使用哈希算法实现Map的另外一个不同之处是:哈希并不会保存元素的顺序,而跳表内所有的元素都是排序的。因此在对跳表进行遍历时,你会得到一个有序的结果。
Node数据结构:
static final class Node<K, V> {
final K key;
volatile Object value;
volatile Node<K, V> next;
}
对Node的所有操作,使用的CAS方法:
boolean casValue(Object cmp, Object val) {
return UNSAFE.compareAndSwapObject(this, valueOffset, cmp, val);
}
boolean canNext(Node<K, V> cmp, Node<K, V> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
Index:索引。它内部包装了Node,同时增加了向下的引用和向右的引用。
static class Index<K, V> {
final Node<K, V> node;
final Index<K, V> down;
volatile Index<K, V> right;
}
整个跳表就是根据Index进行全网的组织的。
此外,对于每一层的表头,还需要记录当前处于哪一层。为此,还需要一个称为HeadIndex的数据结构,表示链表头部的第一个Index。它继承自Index。
static final class HeadIndex<K, V> extends Index<K, V> {
final int level;
HeadIndex(Node<K, V> node, Index<K, V> down, Index<K, V> right, int level) {
super(node, down, right);
this.level = level;
}
}
3.4 参考资料
4. 锁的优化及注意事项
4.1 有助于提高“锁”性能的几点建议
“锁”的竞争必然会导致程序的整体性能下降。
4.1.1 减小锁持有时间
减少锁的持有时间有助于降低锁冲突的可能性,进而提升系统的并发能力。
4.1.2 减小锁粒度
所谓减少锁粒度,就是指减小锁定对象的范围,从而减少锁冲突的可能性,进而提高系统的并发能力。
对于ConcurrentHashMap,它内部进一步细分了若干个小的HashMap,称之为段(SEGMENT)。默认情况下,一个ConcurrentHashMap被进一步细分为16个段。
如果需要在ConcurrentHashMap中增加一个新的表项,并不是将整个HashMap加锁,而是首先根据hashcode得到该表项应该被存放到哪个段中,然后对该段加锁,并完成put()操作。
但是,减少锁粒度会引入一个新的问题,即:当系统需要取得全局锁时,其消耗的资源会比较多。比如试图访问ConcurrentHashMap全局信息时(如size()方法),就会需要同时取得所有段的锁方能顺利实施。
因此,只有类似于size()获取全局信息的方法调用并不频繁时,这种减小锁粒度的方法才能真正意义上提高系统吞吐量。
4.1.3 读写分离锁来替换独占锁
在读多写少的场合,使用读写锁可以有效提升系统的并发能力。
4.1.4 锁分离
如果将读写锁的思想做进一步的延伸,就是锁分离。依据应用程序的功能特点,使用类似的分离思想,也可以对独占锁进行分离。
通过takeLock和putLock两把锁,LinkedBlockingQueue实现了取数据和写数据的分离,使两者在真正意义上成为可并发的操作。
4.1.5 锁粗化
虚拟机在遇到一连串连续地对同一锁不断进行请求和释放的操作时,便会把所有的锁操作整合成对锁的一次请求,从而减少对锁的请求同步次数,这个操作叫做锁的粗化。
在开发过程中,也应该有意识地在合理的场合进行锁的粗化。如:
for (int i = 0; i < CIRCLE; i++) {
synchronized(lock) {
}
}
应粗化为:
synchronized(lock) {
for (int i = 0; i < CIRCLE; i++) {
}
}
性能优化就是根据运行时的真实情况对各个资源点进行权衡折中的过程。锁粗化的思想和减少锁持有时间是相反的,但在不同的场合,它们的效果并不相同。所以大家需要根据实际情况,进行权衡。
4.2 Java虚拟机对锁优化所做的努力
4.2.1 锁偏向
核心思想:如果一个线程获得了锁,那么锁就进入了偏向模式。当这个线程再次请求锁时,无须再做任何同步操作。这样就节省了大量有关锁申请的操作,从而提高了程序性能。因此,对于几乎没有锁竞争的场合,偏向锁有比较好的优化效果,因为连续多次极有可能是同一个线程请求相同的锁。使用Java虚拟机参数-XX+UseBiasedLocking可以开启偏向锁。
4.2.2 轻量级锁
如果偏向锁失效,虚拟机并不会立即挂起线程,它还会使用一种称为轻量级锁的优化手段。轻量级锁的操作也很轻便,它只是简单地将对象头部作为指针,指向持有锁的线程堆栈的内部,来判断一个线程是否持有对象锁。如果线程获得轻量级锁成功,则可以顺利进入临界区。如果轻量级锁加锁失败,则表示其他线程抢先争夺到了锁,那么当前线程的锁请求就会膨胀为重量级锁。
4.2.3 自旋锁
锁膨胀后,虚拟机为了避免线程真实地在操作系统层面挂起,虚拟机还会在做最后的努力——自旋锁。它会假设在不久的将来,线程可以得到这把锁。因此虚拟机会让当前线程做几个空循环,在经过若干次循环后,如果可以得到锁,那么久顺利进入临界区。如果还不能获得锁,才会真实地将线程在操作系统层面挂起。
4.2.4 锁消除
锁消除是一种更彻底的锁优化。Java虚拟机在JIT编译时,通过对运行上下文的扫描,去除不可能存在共享资源竞争的锁。通过锁消除,可以节省毫无意义的请求锁时间。
public String[] createStrings() {
Vector<String> v = new Vector<String>();
for (int i = 0; i < 100; i++) {
v.add(Integer.toString(i));
}
return v.toString(new String[]());
}
锁消除涉及的一项关键技术为逃逸分析,所谓逃逸分析就是观察某一个变量是否会逃出某一个作用域。在本例中,变量v显然没有逃出createStrings()函数之外。以此为基础,虚拟机才可以大胆地将v内部的加锁操作去除。
逃逸分析必须在-server模式下进行,可以使用-XX:+DoEscapeAnalysis参数打开逃逸分析,使用-XX:+EliminateLocks参数可以打开锁消除。
4.3 人手一支笔:ThreadLocal
4.3.1 ThreadLocal的简单使用
static ThreadLocal<SimpleDateFormat> t1 = new ThreadLocal<SimpleDateFormat>();
public static class ParseDate implements Runnable {
int i = 0;
public ParseDate(int i) {
this.i = i;
}
public void run() {
try {
if (t1.get() == null) {
t1.set(new SimpleDateFormat("yyyy-MM-dd HH:mm:SS"));
}
Date t = t1.get.parse("2015-03-29 19:29:" + i % 60);
System.out.println(i + ":" + t);
} catch (ParseException e) {
e.printStackTrace();
}
}
}
为每一个线程分配不同的对象,需要在应用层面保证。ThreadLocal只是起到了简单的容器作用。
4.3.2 ThreadLocal的实现原理
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
map.set(this, value);
} else {
createMap(t, value);
}
}
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
return (T) e.value;
}
}
return setInitialValue();
}
当线程退出时,Thread类会进行一些清理工作,其中就包括清理ThreadLocalMap。
如果我们使用线程池,那就意味着当前线程未必会退出(比如固定大小的线程池,线程总是存在)。如果这样,将一些大大的对象设置到ThreadLocal中(它实际保存在线程持有的threadLocal Map内),可能会使系统出现内存泄露的可能(设置了对象到ThreadLocal中,但不清理它,在你使用几次后,这个对象也不再有用了,但是它却无法被回收).
如果希望及时回收对象,最好使用ThreadLocal.remove()方法将这个变量移除。
如果对于ThreadLocal的变量,我们手动将其设置为null,那么这个ThreadLocal对应的所有线程的局部变量都有可能被回收。
ThreadLocalMap类似WeakHashMap,它的实现使用了弱引用。弱引用是比强引用弱的多的引用。Java虚拟机在垃圾回收时,如果发现弱引用,就会立即回收。ThreadLocalMap内部由一系列Entry构成,每个Entry都是WeakReference
static class Entry extends WeakReference<ThreadLocal> {
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v ;
}
}
当ThreadLocal的外部引用被回收时,ThreadLocalMap中的key就会变为null。当系统进行ThreadLocalMap清理时,就会自然将这些垃圾数据回收。
4.3.3 对性能有何帮助
如果共享对象对于竞争的处理容易引起性能损失,我们还是应该考虑使用ThreadLocal为每个线程分配单独的对象。如多线程下产生随机数。
4.4 无锁
对于并发控制而言,锁是一种悲观的策略,它总是假设每一次的临界区操作会产生冲突。而无锁是一种乐观的策略,它会假设对资源的访问时没有冲突的,一旦遇到冲突,无锁的策略使用一种叫做比较交换的技术(CAS Compare And Swap)来鉴别线程冲突,一旦检测到冲突产生,就重试当前操作直到没有冲突为止。
4.4.1 与众不同的并发策略:比较交换(CAS)
CAS算法的过程是这样:它包含三个参数CAS(V, E, N)。V表示要更新的变量,E表示预期值,N表示新值。仅当V值等于E值时,才会将V的值设为N,如果V值和E值不同,则说明已经有其他线程做了更新,则当前线程什么都不做。
在硬件层面,大部分的现代处理器都已经支持原子化的CAS指令。在JDK 5.0以后,虚拟机便可以使用这个指令来实现并发操作和并发数据结构,并且,这种操作在虚拟机中可以说是无处不在。
4.4.2 无锁的线程安全整数:AtomicInteger
与Integer不同,AtomicInteger是可变的,并且是线程安全的。对其进行修改等任何操作,都是用CAS指令进行的。
就内部实现上说,AtomicInteger中保存一个核心字段:
private volatile int value;
它就代表了AtomicInteger的当前实际值。此外还有一个:
private static final long valueOffset;
它保存着value字段在AtomicInteger对象中的偏移量。
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next)) {
return next;
}
}
}
其中get()方法非常简单:
public final int get() {
return value;
}
和AtomicInteger类似的类还有AtomicLong用来代表long型,AtomicBoolean表示boolean型,AtomicReference表示对象引用。
4.4.3 Java中的指针:Unsafe类
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
变量unsafe是sun.misc.Unsafe类型。这里的Unsafe就是封装了一些类似指针的操作。compareAndSwapInt()方法是一个native方法,它的几个参数含义如下:
public final native boolean compareAndSwapInt(Object o, long offset, int expected, int x);
第一个参数o为给定的对象,offset为对象内的偏移量,expected表示期望值,x表示要设置的值。如果指定的字段的值等于expected,那么就会把它设置为x。
compareAndSwapInt()方法的内部,必然是使用CAS原子指令来完成的。
JDK的开发人员并不希望大家使用Unsafe这个类:
public static Unsafe getUnsafe() {
Class cc = Reflection.getCallerClass();
if (cc.getClassLoader() != null) {
throw new SecurityException("Unsafe");
}
return theUnsafe;
}
根据Java类加载器的工作原理,应用程序的类由AppLoader加载。而系统核心类,如rt.jar中的类由Bootstrap类加载器加载。Bootstrap加载器没有Java对象的对象,因此试图获得这个类加载器会返回null。所以,当一个类的类加载器为null时,说明它是由Bootstrap加载的,而这个类也极有可能是rt.jar中的类。
4.4.4 无锁的对象引用:AtomicReference
AtomicReference对应普通对象的引用,它可以保证你在修改对象引用时的线程安全性。
static AtomicReference<Integer> money = new AtomicReference<Integer>();
不足:当你获得对象当前的数据后,在准备修改为新值前,对象的值被其他线程连续修改了两次,而经过这两次修改后,对象的值又恢复为旧值。这样,当前线程就无法正确判断这个对象究竟是否被修改过。
JDK已经为我们考虑到了这种情况,使用AtomicStampedReference就可以很好地解决这个问题。
4.4.5 带有时间戳的对象引用:AtomicStampedReference
只要能够记录对象在修改过程中的状态值,就可以很好地解决对象被反复修改导致线程无法正确判断对象状态的问题。
AtomicStampedReference内部不仅维护了对象值,还维护了一个时间戳。
4.4.6 数组也能无锁:AtomicIntegerArray
当前可用的原子数组有;AtomicIntegerArray、AtomicLongArray和AtomicReferenceArray,分别表示整数数组、long型数组和普通的对象数组。
AtomicIntegerArray本质上是对int[]类型的封装,使用Unsafe类通过CAS的方式控制int[]在多线程下的安全性。
public class AtomicIntegerArrayDemo {
static AtomicIntegerArray arr = new AtomicIntegerArray[10];
public static AddThread implements Runnable {
public void run() {
for (int k = 0; k < 10000; k++) {
arr.getAndIncrement(k % arr.length);
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread[] ts = new Thread[10];
for (int k = 0; k < 10; k++) {
ts[k] = new Thread(new AddThread());
}
for (int k = 0; k < 10; k++) {
ts[k].start();
}
for (int k = 0; k < 10; k++) {
ts[k].join();
}
System.out.println(arr);
}
}
4.4.7 让普通变量也享受原子操作:AtomicIntegerFieldUpdater
AtomicIntegerFieldUpdater可以让你在不改动(或者极少改动)原有代码的基础上,让普通的变量也享受CAS操作带来的线程安全性,这样你可以修改极少的代码,来获得线程安全的保证。
根据数据类型不同,这个Updater有三种,分别是AtomicIntegerFieldUpdater、AtomicLongFieldUpdater和AtomicReferenceFieldUpdater。它们分别可以对int、long和普通对象进行CAS修改。
public class AtomicIntegerFieldUpdaterDemo {
public static class Candidate {
int id;
volatile int score;
}
public final static AtomicIntegerFieldUpdater<Candidate> scoreUpdater = AtomicIntegerFieldUpdater.newUpdater(Candidate.class, "score");
// 检查Updater是否工作正确
public static AtomicInteger allScore = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
final Candidate stu = new Candidate();
Thread[] t = new Thread[10000];
for (int i = 0; i < 10000; i++) {
t[i] = new Thread() {
public void run() {
if (Math.random() > 0.4) {
scoreUpdater.incrementAndGet(stu);
allScore.incrementAndGet();
}
}
};
t[i].start();
}
for (int i = 0; i < 10000; i++) {
t[i].join();
}
System.out.println("score=" + stu.score);
System.out.println("allScore=" + allScore);
}
}
虽然AtomicIntegerFieldUpdater最好用,但是还是有几个注意事项:
- 第一,Updater只能修改它可见范围内的变量。因为Updater使用反射得到这个变量。如果变量不可见,就会出错。比如如果score申明为private,就是不可行的。
- 第二,为了确保变量被正确的读取,它必须是volatile类型的。
- 第三,由于CAS操作会通过对象实例中的偏移量进行赋值,因此,它不支持static字段(Unsafe.objectFieldOffset()不支持静态变量)。
4.4.8 挑战无锁算法:无锁的Vector实现
无锁的好处:
- 第一,在高并发的情况下,它比有锁的程序拥有更好的性能。
- 第二,它天生就是死锁免疫的。
就凭借这两个优势,就值得我们冒险尝试使用无锁的并发。
无锁的Vector来自于amino并发包。
4.4.9 让线程之间互相帮助:细看SynchronousQueue的实现
SynchronousQueue的容量为0,任何一个对SynchronousQueue的写需要等待一个对SynchronousQueue的读,反之亦然。SynchronousQueue与其说是一个队列,不如说是一个数据交换通道。
对SynchronousQueue来说,它将put()和take()两个功能截然不同的操作抽象为一个共通的方法Transformer.transfer()。
Object transfer(Object e, boolean timed, long nanos);
当参数e为非空时,表示当前操作传递给一个消费者,如果为空,则表示当前操作需要请求一个数据。timed参数决定是否存在timeout时间,nanos决定了timeout的时长。如果返回值非空,则表示数据已经接受或者正常提供,如果为空,则表示失败(超时或者中断)。
SynchronousQueue内部会维护一个线程等待队列。等待队列中会保存等待线程以及相关数据的信息。比如,生产者将数据放入SynchronousQueue时,如果没有消费者接收,那么数据本身和线程对象都会打包在队列中等待。
Transferer.transfer()函数的实现是SynchronousQueue的核心,它大体上分为三个步骤:
- 如果等待队列为空,或者队列中节点的类型和本次操作是一致的,那么将当前操作压入队列等待。比如,等待队列中是读线程等待,本次操作也是读,因此这两个读都需要等待。进入等待队列的线程可能会被挂起,它们会等待一个“匹配”操作。
- 如果等待队列中的元素和本次操作是互补的(比如等待操作是读,而本次操作是写),那么就插入一个“完成”状态的节点,并且让他“匹配”到一个等待节点上。接着弹出这两个节点,并且使得对应的两个线程继续执行。
- 如果线程发现等待队列的节点就是“完成”节点,那么帮助这个节点完成任务。其流程和步骤2是一致的。
从整个数据投递的过程中可以看到,在SynchronousQueue中,参与工作的所有线程不仅仅是竞争资源的关系。更重要的是,它们彼此之间还会互相帮助。在一个线程内部,可能会帮助其他线程完成它们的工作。这种模式可以更大程度上减少饥饿的可能,提高系统整体的并行度。
4.5 有关死锁的问题
死锁就是两个或者多个线程,相互占用对方需要的资源,而都不进行释放,导致彼此之间都相互等待对方释放资源,产生了无限制等待的现象。
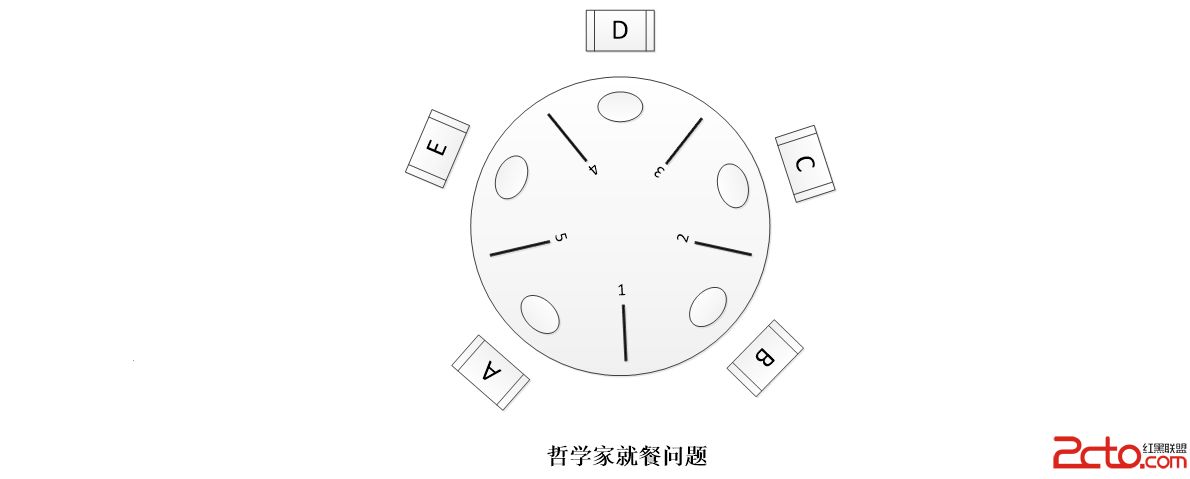
我们可以使用jps命令得到java进程的进程ID,接着使用jstack命令得到线程的线程堆栈:
$ jps
8404
944
3892 DeadLock
3260 Jps
$ jstack 3992
...
如果想避免死锁,除了使用无锁的函数外,另外一种有效的做法是使用重入锁,通过重入锁的中断或者限时等待可以有效规避死锁带来的问题。
4.6 参考文献
第5章 并行模式与算法
5.1 探讨单例模式
单例模式是一种对象创建模式,用于产生一个对象的具体实例,它可以确保系统中一个类只产生一个实例。好处有:
- 对于频繁使用的对象,可以省略new操作花费的时间,这对于那些重量级对象而言,是非常可观的一笔系统开销;
- 由于new操作的次数减少,因而对系统内存的使用频率也会降低,这将减轻GC压力,缩短GC停顿时间。
一个正确良好的实现:
public class Singleton {
private Singleton() {
System.out.println("Singleton is create");
}
private static Singleton instance = new Singleton();
public static Singleton getInstance() {
return instance;
}
}
明显不足:
Singleton实例在什么时候创建是不受控制的。对于静态成员instance,它会在类第一次初始化的时候被创建。这个时刻并不一定是getInstance()方法第一次被调用的时候。
LazySingleton:
public class LazySingleton {
private LazySingleton {
System.out.println("LazySingleton is create");
}
private static LazySingleton instance = null;
public static synchronized LazySingleton getInstance() {
if (instance == null) {
instance = new LazySingleton();
}
return instance;
}
}
好处:充分利用了延迟加载,只在真正需要时创建对象。
坏处:并发环境下加锁,竞争激烈的场合对性能可能产生一定的影响。
结合两者之优势的方法:
public class StaticSingleton {
private StaticSingleton() {
System.out.println("StaticSingleton is create");
}
private static class SingletonHolder {
private static StaticSingleton instance = new StaticSingleton();
}
public static StaticSingleton getInstance() {
return SingletonHolder.instance;
}
}
5.2 不变模式
不变模式天生就是多线程友好的,它的核心思想是,一个对象一旦被创建,则它的内部状态将永远不会发生改变。所以,没有一个线程可以修改其内部状态和数据,同时其内部状态也绝不会自行发生改变。基于这些特性,对不变对象的多线程操作不需要进行同步控制。
不变欧式是比只读属性具有更强的一致性和不变性,对只读属性的对象而言,对象本身不能被其他线程修改,但是对象的自身状态却可能自行修改。
不变模式的主要使用场景需要满足以下2个条件:
- 当对象创建后,其内部状态和数据不再发生任何变化。
- 对象需要被共享,被多线程频繁访问。
在Java语言中,不变模式的实现很简单,只需要注意以下4点:
- 去除setter方法以及所有修改自身属性的方法。
- 将所有属性设置为私有,并用final标记,确保其不可修改。
- 确保没有子类可以重载修改它的行为。
- 有一个可以创建完整对象的构造函数。
示例代码:
public final class Product {
private final String no;
private final String name;
private final double price;
public Product(String no, String name, double price) {
super();
this.no = no;
this.name = name;
this.price = price;
}
public String getNo() {
return no;
}
public String getName() {
return name;
}
public double getPrice() {
return price;
}
}
在JDK中,主要的不变模式类型如下:
- java.lang.String
- java.lang.Boolean
- java.lang.Byte
- java.lang.Character
- java.lang.Double
- java.lang.Float
- java.lang.Integer
- java.lang.Long
- java.lang.Short
不变模式通过回避问题而不是解决问题的态度来处理多线程并发访问控制。不变对象实不需要进行同步操作的。由于并发同步会对性能产生不良的影响,因此,在需求允许的情况下,不变模式可以提高系统的并发性能和并发量。
5.3 生产者-消费者模式
生产者-消费者模式是一个经典的多线程设计模式,它为多线程间的协作提供了良好的解决方案。在生产者-消费者模式中,通常有两类线程,即若干个生产者线程和若干个消费者线程。生产者线程负责提交用户请求,消费者线程则负责具体处理生产者提交的任务。生产者和消费者之间则通过共享内存缓冲区进行通信。
生产者-消费者模式中的内存缓存区的主要功能是数据在多线程间的共享,此外,通过该缓冲区,可以缓解生产者和消费者间的性能差。
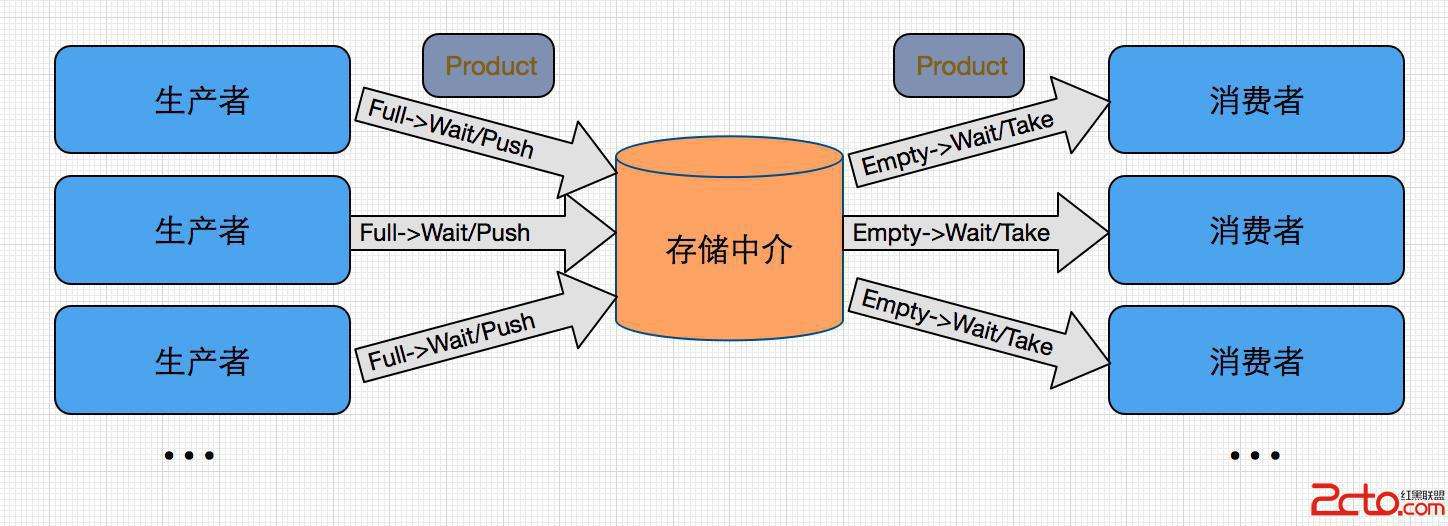
生产者-消费者模式的主要角色:
- 生产者:用于提交用户请求,提取用户任务,并装入内存缓冲区。
- 消费者:在内存缓冲区中提取并处理任务。
- 内存缓冲区:缓存生产者提交的任务或数据,供消费者使用
- 任务:生产者向内存缓冲区提交的数据结构
- Main:使用生产者和消费者的客户端
生产者-消费者模式很好地对生产者和消费者线程进行解耦,优化了系统整体结构。同时,由于缓冲区的作用,允许生产者线程和消费者线程存在执行上的性能差异,从一定程度上缓解了性能瓶颈对系统性能的影响。
5.4 高性能的生产者-消费者:无锁的实现
BlockingQueue用于实现生产者和消费者一个不错的选择。但是BlockingQueue并不是一个高性能的实现,它完全使用锁和阻塞等待来实现线程间的同步。在高并发场合,它的性能并不是特别的优越。
如果我们使用CAS来实现生产者-消费者模式,也同样可以获得可观的性能提升。
5.4.1 无锁的缓存框架:Disruptor
Disruptor使用无锁的方式实现了一个环形队列,非常适合于实现生产者和消费者模式,比如事件和消息的发布。在Disruptor中,别出心裁地使用了环形队列(RingBuffer)来代替普通线性队列,这个环形队列内部实现为一个普通的数组。Disruptor要求我们必须将数组的大小设置为2的整数次方。这样通过sequence & (queueSize - 1)就能立即定位到实际的元素位置index。这个要比取余(%)操作快得多。
RingBuffer的结构:生产者向缓冲区中写入数据,而消费者从中读取数据。生产者写入数据时,使用CAS操作,消费者读取数据时,为了防止多个消费者处理同一个数据,也使用CAS操作进行数据保护。
这种固定大小的环形队列的另外一个好处就是可以做到完全的内存复用。在系统的运行过程中,不会有新的空间需要分配或者老的空间需要回收。因此,可以大大减少系统分配空间以及回收空间的额外开销。
5.4.2 用Disruptor实现生产者-消费者案例
根据Disruptor的官方报告,Disruptor的性能要比BlockingQueue至少高一个数量级以上。
5.4.3 提高消费者的相应时间:选择合适的策略
消费者如何监控缓冲区中的信息呢?为此,Disruptor提供了几种策略,这些策略由WaitStrategy接口进行封装,主要实现有:
- BlockingWaitStrategy:默认的策略,最节省CPU,但在高并发下性能表现最糟糕。
- SleepingWaitStrategy:对CPU使用率也非常保守,有较高的平均延时,比较适合于对延时要求不是特别高的场合,好处是它对生产者线程的影响最小(典型场景:异步日志)。
- YieldingWaitStrategy:用于低延时的场合。
- BusySpinWaitStrategy:最疯狂的等待策略,就是一个死循环,消费者线程尽最大努力疯狂监控缓冲区的变化。它会吃掉所有的CPU资源。
5.4.4 CPU Cache的优化:解决伪共享问题
什么是伪共享?为了提高CPU的速度,CPU有一个高速缓存Cache。在高速缓存中,读写数据的最小单位为缓存行(Cache Line),它是从主存(memory)复制到缓存(Cache)的最小单位,一般为32字节到128字节。
如果两个变量存放在一个缓存行中时,在多线程访问中,可能会相互影响彼此的性能。假设X和Y在同一个缓存行。运行在CPU1上的线程更新了X,那么CPU2上的缓存行就会失效,同一行的Y即使没有修改也会变成无效,导致Cache无法命中。这种情况反反复复发生,无疑是一个潜在的性能杀手。如果CPU经常不能命中缓存,那么系统的吞吐量就会急剧下降。
为了使这种情况不发生,一种可行的做法就是在X变量的前后空间都先占据一定的位置(把它叫做padding吧,用来填充的)。
由于各个JDK版本内部实现不一致,在某些JDK版本中(比如JDK 8),会自动优化不使用的字段。这将直接导致这种padding的伪共享解决方案失效。
Disruptor框架的核心组件Sequence中,主要使用的只有value。但是,通过LhsPadding和RhsPadding,在这个value的前后安置了一些占位空间,使得value可以无冲突的存在于缓冲中。
此外,对于Disruptor的环形缓冲区RingBuffer,它内部的数组是通过以下语句构造的:
this.entries = new Object[sequencer.getBufferSize() + 2 * BUFFER_PAD];
相当于在这个数组的头部和尾部两段各增加了BUFFER_PAD个填充,使得整个数组被载入Cache时不会受到其他变量的影响而失效。
5.5 Future模式
对于Future模式来说,虽然它无法立即给出你需要的数据。但是,它会返回给你一个契约,将来,你可以凭借着这个契约区重新获取你需要的信息。
5.5.1 Future模式的主要角色
- Main:系统启动,调用Client发出请求
- Client:返回Data对象,立即返回FutureData,并开启ClientThread线程装配RealData
- Data:返回数据的接口
- FutureData:Future数据,构造很快,但是是一个虚拟的数据,需要装配RealData
- RealData:真实数据,其构造是比较慢
5.5.2 Future模式的简单实现
Data接口:
public interface Data {
public String getResult();
}
FutureData实现了一个快速返回的RealData包装。
public class FutureData implements Data {
protected RealData realdata = null;
protected boolean isReady = false;
public synchronized void setRealData(RealData realdata) {
if (isReady) {
return;
}
this.realdata = realdata;
isReady = true;
notifyAll();
}
public synchronized String getResult() {
while (!isReady) {
try {
wait();
} catch (InterruptedException e) {
}
}
return realdata.result;
}
}
ReadData是最终需要使用的数据模型。它的构造很慢。
public class RealData implements Data {
protected final String result;
public RealData(String para) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 10; i++) {
sb.append(para);
try {
// 这里使用sleep代替一个很慢的操作过程
Thread.sleep(100);
} catch (InterruptedException e) {
}
}
result = sb.toString();
}
public String getResult() {
return result;
}
}
Client主要实现了获取FutureData,并开启构造RealData的线程,并在接受请求后,很快的返回FutureData,它不会等待数据真的构造完毕再返回,而是立即返回FutureData。
public class Client {
public Data request(final String queryStr) {
final FutureData future = new FutureData();
new Thread() {
public void run() {
RealData realdata = new RealData(queryStr);
future.setRealData(realdata);
}
}.start();
return future;
}
}
最后,就是我们的主函数Main,它主要负责调用Client发起请求,并消费返回的数据。
public static void main(String[] args) {
Client client = new Client();
Data data = client.request("name");
System.out.println("请求完毕");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
}
System.out.println("数据 = " + data.getResult());
}