原文:
https://mp.weixin.qq.com/s/kfFh7I_V5haghV6qUzHtag
OLAP(联机分析处理)是数据仓库的主要应用之一,通过设计维度、度量,我们可以构建星型模型或雪花模型,生成数据多维立方体Cube,基于Cube可以做钻取、切片、旋转等多维分析操作。早在十年前,SQL Server、Oracle 等数据库软件就有OLAP产品,为用户提供关系数据库、多维数据集、可视化报表的整套商业智能方案。
随着大数据的发展,Kylin、Druid、Presto 等基于大数据的OLAP开源工具开始涌现,我们可以对亿级的数据进行OLAP分析。Kylin 就是一款基于Hive的开源OLAP工具,我们可以设计Hive表的字段为维度和度量,通过Kylin来构建Cube,Kylin会将Cube结构存储在 HBase 之上,基于Cube我们可以做各种多维分析。在推荐系统开发过程中,我们往往需要按场景、策略、平台等多个不同维度来比较效果数据,推荐系统的线上效果评价是一个很强的多维分析应用场景。因此,我们基于Kylin搭建了推荐系统效果评价系统。
1 背景介绍
五八同城智能推荐系统是一个通用的推荐平台,旨在为五八同城不同业务线提供推荐服务。目前,我们接入了不同业务线在APP、PC、M三端上共计约六十个推荐位,包括大类页、列表页、详情页、公共页(如APP首页、消息中心页等)等推荐场景。在一些核心推荐位上,我们会持续迭代召回策略、排序算法以及展示样式,以不断优化推荐效果。比较和分析不同业务线、不同推荐场景、不同推荐算法的效果是我们的基础工作,早期我们是通过 Hive + MySQL的方式来实现效果数据的统计分析,但耗费了大量人力。在数据平台提供了Kylin服务之后,我们基于Kylin重构了我们的推荐系统效果评价系统,大大节约了人力成本,提高了开发效率。
2 Apache Kylin基本原理和架构
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,能够支持TB到PB级别的数据量,最初由eBay Inc开发并于2014年10月贡献至开源社区,于2014年11月加入Apache孵化器项目,于2015年11月正式毕业成为Apache 顶级项目。
2.1 名词、概念解释
- 事实表:事实表是用来记录具体事件的,包含了每个事件的具体要素,以及具体发生的事情。
- 维表:维表包含对事实表的某些列进行扩充说明的字段。
- 星型模式:包含一个或多个事实表、一组维表,以及事实表与维表的join方式。
- 度量:度量是具体考察的聚合数量值,例如:销售数量、销售金额、人均购买量。计算机一点描述就是在SQL中就是聚合函数。
- 维度:维度是观察数据的角度。例如:销售日期、销售地点。计算机一点的描述就是在SQL中就是where、group by里的字段
- 预计算结果:预计算结果是对事实表进行预计算的结果,预计算结果以键值对形式存在,键是维度的特定值、值是对应的度量值,一条预计算结果有一个对应的维度集合。
- 预计算结果全集:全部预计算结果组成的集合。
- cuboid:预计算结果全集中对应的维度集合相同的预计算结果的集合。
- cuboid树:若干个不同的cuboid组成的有向树,满足孩子对应的维度集合是父亲对应维度集合的子集。
- Cube:Cube是一个集合,包含若干个cuboid。
2.2 Apache Kylin核心思想
简单来说,Kylin的核心思想是预计算,用空间换时间,即对多维分析可能用到的度量进行预计算,将计算好的结果保存成Cube,供查询时直接访问。把高复杂度的聚合运算、多表连接等操作转换成对预计算结果的查询,这决定了Kylin能够拥有很好的快速查询和高并发能力。
2.3 Apache Kylin架构
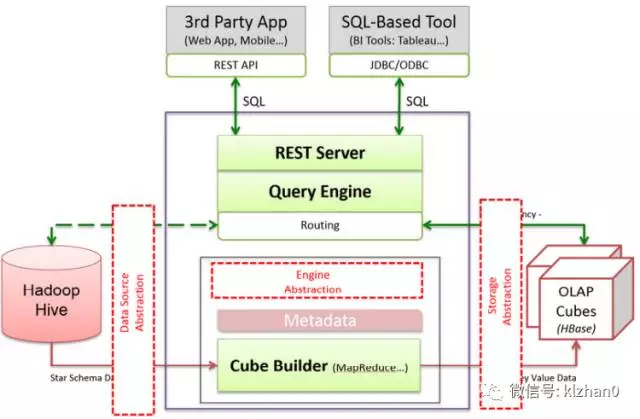
kylin由以下及部分组成:
- REST Server:提供一些restful接口,例如创建cube、构建cube、刷新cube、合并cube等cube的操作,project、table、cube等元数据管理、用户访问权限、系统配置动态修改等。除此之外还可以通过该接口实现SQL的查询,这些接口一方面可以通过第三方程序的调用,另一方也被kylin的web界面使用。
- jdbc/odbc接口:kylin提供了jdbc的驱动,驱动的classname为org.apache.kylin.jdbc.Driver,使用的url的前缀jdbc:kylin:,使用jdbc接口的查询走的流程和使用RESTFul接口查询走的内部流程是相同的。这类接口也使得kylin很好的兼容tebleau甚至mondrian。
- Query引擎:kylin使用一个开源的Calcite框架实现SQL的解析,相当于SQL引擎层。
- Routing:该模块负责将解析SQL生成的执行计划转换成cube缓存的查询,cube是通过预计算缓存在hbase中,这部分查询是可以在秒级甚至毫秒级完成,而还有一些操作使用过查询原始数据(存储在hadoop上通过hive上查询),这部分查询的延迟比较高。
- Metadata:kylin中有大量的元数据信息,包括cube的定义,星型模型的定义、job的信息、job的输出信息、维度的directory信息等等,元数据和cube都存储在hbase中,存储的格式是json字符串,除此之外,还可以选择将元数据存储在本地文件系统。
- Cube构建引擎:这个模块是所有模块的基础,它负责预计算创建cube,创建的过程是通过hive读取原始数据然后通过一些mapreduce计算生成Htable然后load到hbase中。
2.4 Kylin的Cube优化
计算Cube的存储代价以及计算代价都是比较大的, 传统OLAP的维度爆炸的问题Kylin也一样会遇到。 Kylin提供给用户一些优化措施,在一定程度上能降低维度爆炸的问题。
在业务分析中有许多cuboid是我们不会用到的。例如我们的推荐中我们不会分析没有date维度的cuboid,就是说我们不会不指定日期来分析数据;我们在分析cuboid中带recname的时候,就一定有scene,就是说我们在分析数据recname的时候,一定会同时分析scene。
我们可以不存储也不计算这些我们不需要的cuboid。这样就节省了很大的硬盘空间和Cube构建时间。这些都是Cube可以优化的空间。
Kylin的4种维度类型:
- 普通维度(General dimension):普通维度是不做任何优化的维度。有n个普通维度的Cube的cuboid的数量为2^n
- 强制维度(Mandatory Dimensions):强制维度是Cube中所有cuboid中必有的维度。强制维度可以使Cube的cuboid减少一半。
- 层级维度(Hierarchy Dimensions),层级维度是有层次关系的维度,使得cuboid中低层次的维度总是伴随着高层次维度的出现。一个有n个层次的层次维度可以使cuboid的数量从2^n降到n+1。例如 年、月、日 可以作为3个层级的层级维度
- 组合维度(Joint Dimensions),组合维度是将几个维度组合成一个维度,使得这几个维度在cuboid中总是同时出现或总是同时不出现。一个有n个维度的组合维度可以使cuboid数量从2^n降到2。 例如 年、月、日 可以作为有3个维度的组合维度(日期)。
2.5 Kylin的distinct count聚合计算
Kylin中的度量,例如count、max、min、sum大部分我们都能理解是如何计算的,但count(distinct xxx)(UV)是如何计算的呢?
在Kylin有两中方式计算UV:
- 第一种是近似Count Distinct。使用HyperLogLog算法实现了近似Count Distinct,提供了错误率从9.75%到1.22%几种精度供选择。算法计算后的Count Distinct指标,理论上,结果最大只有64KB,最低的错误率是1.22%。这种实现方式用在需要快速计算、节省存储空间,并且能接受错误率的Count Distinct指标计算。
- 第二种是精准Count Distinct。使用bitmap数据类型来做标记,虽然是bitmap类型,但不是真正的位图,而是被当成了类似C++的bitset的数据结构。当数据类型为int、short int、tiny等32位以内的数值型时,会直接映射到bitmap上,当数据类型为long、string等其他类型时,会将数据值以字符串形式编成字典,在将字典上对应的字符串id映射到bitmap。这种实现方式提供了精确的无错误的Count Distinct结果,但是需要更多的存储资源。
2.6 Kylin的Cube构建
逐层算法是构建Cube的一种算法,它将cuboid按对应维度子集中纬度的个数分层。逐层计算cuboid,对维度个数较多的cuboid做聚合操作得到维度个数较少的cuboid。
因为有4层,所以会做4次mapreducer计算。除了第一次mapreducer计算的输入是源数据集外,其他每一次mapreducer计算的输入输出的每一行都是一条预计算结果。
第一次mapreducer将源数据集作为输入,计算并输出第1层的cuboid {{date,platform,algo}},第二次的mapreducer以第一次的mapreducer的输出做为输入,计算得出第二层的第2层的cuboid {{date,platform}, {date,algo}, {platform,algo}}。之后的mapreducer类似第二次的mapreducer。
除了逐层算法,还有快速Cube算法。该算法的主要思想是对Mapper所分配的数据块,将它计算成一个完整的小Cube 段(包含所有Cuboid);每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果。
2.7 参考资料
http://blog.csdn.net/xiao_jun_0820/article/details/50731117
http://webdataanalysis.net/web-data-warehouse/data-cube-and-olap/
http://webdataanalysis.net/web-data-warehouse/multidimensional-data-model/
http://blog.csdn.net/rogerxi/article/details/3966782
http://www.cnblogs.com/en-heng/p/5239311.html
http://www.cnblogs.com/hark0623/p/5521006.html
http://lxw1234.com/archives/2016/08/712.htm
http://www.infoq.com/cn/articles/apache-kylin-algorithm/