
- 第1章 搜索引擎及其技术架构
- 第2章 网络爬虫
第1章 搜索引擎及其技术架构
1.1 搜索引擎为何重要
搜索引擎依托于互联网,互联网的蓬勃发展是搜索引擎产品与技术逐步成熟的大背景。离开互联网,搜索引擎将无从谈起。
1.1.1 互联网的发展
1.1.2 商业搜索引擎公司的发展
Yahoo、Google、百度
1.1.3 搜索引擎的重要地位
搜索引擎已成为互联网最重要的应用之一。
1.2 搜索引擎技术发展史
1.2.1 史前时代:分类目录的一代
导航时代:Yahoo和国内的hao123,纯人工收集整理方式
被收录的网站质量都较高,但是这种方式可扩展性不强,绝大部分网站不能被收录
1.2.2 第一代:文本检索的一代
信息检索模型(布尔模型、向量空间模型、概率模型)计算用户查询关键词和网页文本内容的相关程度。
未使用网页之间丰富的链接关系
这种方式可以收录大部分网页,并能够按照网页内容和用户查询的匹配程度进行排序。但总体而言,搜索结果质量不是很好。
1.2.3 第二代:链接分析的一代
充分利用了网页之间的链接关系,并深入挖掘和利用了网页链接所代表的含义。
通过结合网页流行性和内容相似性来改善搜索质量。
问题:
- 未考虑用户个性化要求,所有用户获得相同的搜索结果。
- 作弊:网站针对链接分析算法提出链接作弊方案。
1.2.4 第三代:用户中心的一代
以理解用户需求为核心。
致力于解决:如何能够理解用户发出的某个很短小的查询词背后包含的真正需求。
技术:
- 利用用户发送查询词时的时间和地理位置信息
- 利用用户过去发出的查询词及相应的点击记录等历史信息等技术手段。
1.3 搜索引擎的3个目标
更全、更快、更准。
1.4 搜索引擎的3个核心问题
1.4.1 3个核心问题
- 用户真正的需求是什么
- 哪些信息是和用户需求真正相关的
- 哪些信息是用户可以信赖的
1.4.2 与技术发展的关系
第三代搜索引擎同时考虑了3个核心问题。
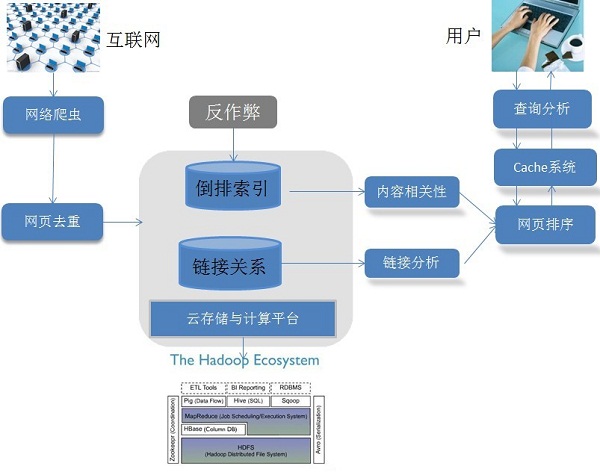
1.5 搜索引擎的技术架构
第2章 网络爬虫
2.1 通用爬虫框架
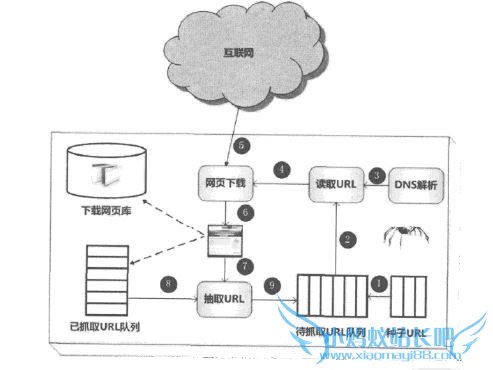
互联网页面划分:
- 已下载网页集合
- 已过期网页集合
- 待下载网页集合
- 可知网页集合
- 不可知网页集合
爬虫3种类型:
- 批量型爬虫(Batch Crawler):有比较明确的抓取范围和目标。
- 增量型爬虫(Incremental Crawler):保持持续不断的抓取,抓取到的网页要定期更新。
- 垂直型爬虫(Focused Crawler):关注特定主题内容或者属于特定行业的网页。
2.2 优秀爬虫的特性
- 高性能:爬虫下载网页的抓取速度(每秒能够下载的网页数量)
- 可扩展性:很容易通过增加抓取服务器和爬虫数量来达到目的。
- 健壮性:
- 友好性:
- 保护网站的部分私密性
- 减少被抓取网站的网络负载
爬虫禁抓协议(Robot Exclusion Protocol):robot.txt
User-agent: GoogleBot
Disallow: /tmp/
Disallow: /cgi-bin/
Disallow: /users/paranold/
网页禁抓标记(Robot META tag)
<meta name="robots" content="noindex"> // 情形一:禁止索引网页内容
<meta name="robots" content="nofollow"> // 情形二:禁止抓取网页链接
2.3 爬虫质量的评价标准
3个标准:
- 抓取网页覆盖率
- 抓取网页时新性
- 抓取网页重要性
爬虫研发的目标:在资源有限的情况下,既然搜索引擎只能抓取互联网现存网页的一部分,那么就尽可能选择比较重要的那部分页面来索引;对于已经抓取到的网页,尽可能快地更新其内容;在此基础上,尽可能扩大抓取范围,抓取到更多以前无法发现的网页。
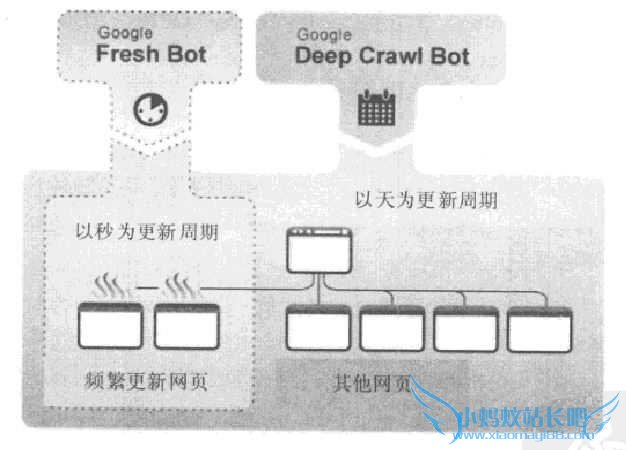
Google的几套爬虫系统:
- Fresh Bot:主要考虑网页的时新性,对于内容更新频繁的网页,达到以秒计的更新周期。
- Deep Crawl Bot:针对其他更新不是那么频繁的网页抓取,以天为更新周期。
- 针对暗网的抓取系统
2.4 抓取策略
目标:优先选择重要网页进行抓取。
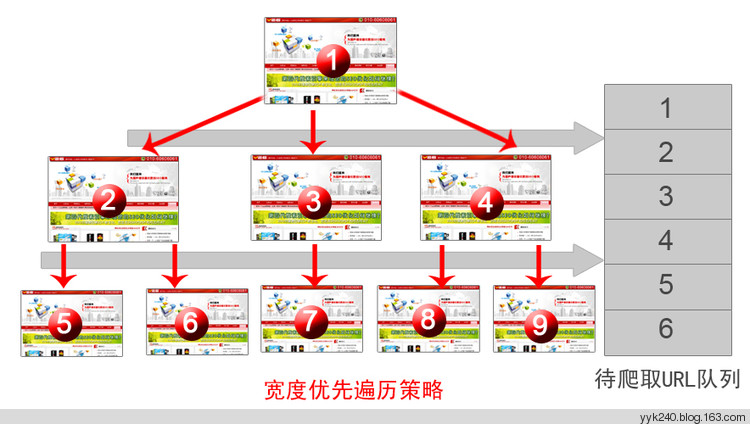
2.4.1 宽度优先遍历策略(Breadth First)
2.4.2 非完全PageRank策略(Partial PageRank)
基本思路:对于已经下载的网页,加上待抓取URL队列中的URL一起,形成网页集合,在此集合内进行PageRank计算,计算完成后,将待抓取URL队列里的网页按照PageRank得分由高到低排序,形成的序列就是爬虫接下来应该依次抓取的URL列表。
2.4.3 OPIC策略(Online Page Importance Computation)
在线页面重要性计算:改进的PageRank算法。
在算法开始之前,每个互联网页面都给予相同的”现金”(cash),每当下载了某个页面P后,P将自己拥有的”现金”平均分配给页面中包含的链接页面,把自己的”现金”清空。
与PageRank思路的区别:
- PageRank每次需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度要远远快于PageRank,适合实时计算使用。
- PageRank在计算时,存在向无链接关系网页的远程跳转过程,而OPIC没有这一计算因子。
实验表明,OPIC是种较好的重要性衡量策略,效果略优于宽度优先遍历策略。
2.4.4 大站优先策略(Larger Sites First)
如果哪个网站等待下载的页面最多,则优先下载这些链接。
2.5 网页更新策略
网页更新策略的任务是要决定何时重新抓取之前已经下载过的网页,以尽可能使得本地下载网页和互联网原始页面内容保持一致。
2.5.1 历史参考策略
假设:过去频繁更新的网页,那么将来也会频繁更新。
往往利用泊松过程来对网页的变化进行建模。
抓取策略应该忽略掉广告栏或者导航栏这种不重要区域的频繁变化,而集中在主题内容的变化探测和建模上。
2.5.2 用户体验策略
用户体验策略保存网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响,得出一个平均值,以此作为判断爬虫重抓该网页时的参考依据,对于影响越厉害的网页,则越优先调度重新抓取。
2.5.3 聚类抽样策略
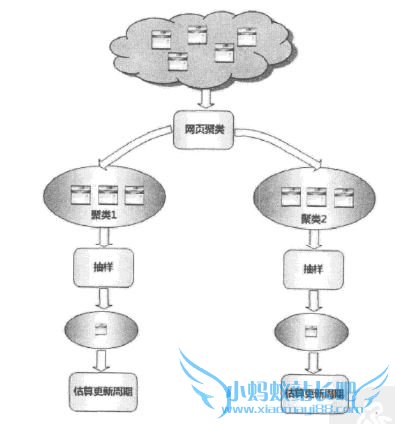
能够体现网页更新周期的属性特征:
- 静态特征:页面的内容、图片数量、页面大小、链接深度、PageRank值等
- 动态特征:体现了静态特征随着时间的变化情况,如图片数量的变化情况、入链出链的变化情况等
相关实验表明,聚类抽样策略效果好于前述两种更新策略,但是对以亿计的网页进行聚类,其难度也是非常巨大的。
2.6 暗网抓取(Deep Web Crawling)
所谓暗网,是指目前搜索引擎爬虫按照常规方式很难抓取到的互联网页面。
暗网爬虫:将暗网数据从数据库挖掘出来,并将其加入搜索引擎的索引,这样用户在搜索时便可利用这些数据,增加信息覆盖程度。
两大技术挑战:
- 查询组合太多,如果一一组合遍历,那么会给被访问网站造成太大压力,所以如何精心组合查询选项是个难点
- 有的查询是文本框,比如图书搜索中需要输入书名,爬虫怎样才能够填入合适的内容?这个也颇具挑战性。
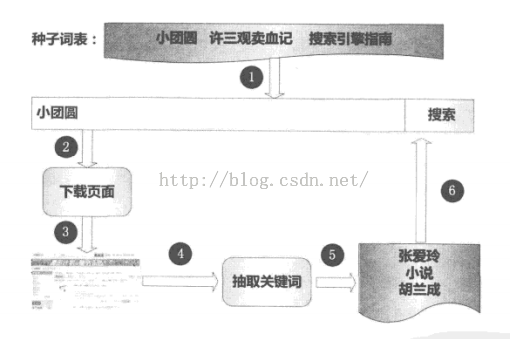
2.6.1 查询组合问题
富含信息查询模板(Informative Query Templates)技术:对于某个固定的查询模板来说,如果给模板内每个属性都赋值,形成不同的查询组合,提交给垂直搜索引擎,观察所有返回页面的内容,如果相互之间内容差异较大,则这个查询模板就是富含信息查询模板。
ISIT算法:首先从一维模板开始,对一维查询模板逐个考察,看其是否富含信息查询模板,如果是的话,则将这个一维模板扩展到二维,再依次考察对应的二维模板,如此类推,逐步增加维数,直到再也无法找到富含信息查询模板为止。(与数据挖掘里经典的Apriori规则挖掘算法有异曲同工之处)
2.6.2 文本框填写问题
对于输入中的文本框,需要爬虫自动生成查询。
2.7 分布式爬虫
大型分布式爬虫的3个层级:
- 分布式数据中心
- 分布式抓取服务器
- 分布式爬虫程序
两种分布式架构:
- 主从分布爬虫
- 对等式分布爬虫
2.7.1 主从分布式爬虫(Master-Slave)
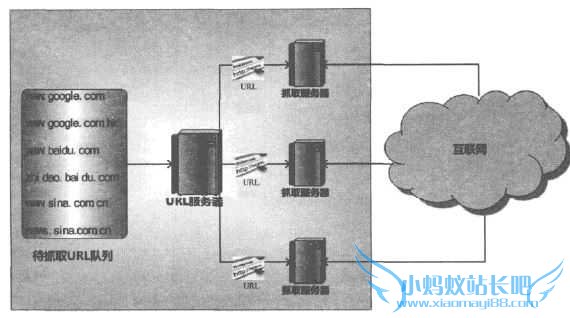
缺点:因为URL服务器承担很多管理任务,同时待抓取URL队列数量巨大,所以URL服务器容易成为整个系统的瓶颈。
2.7.2 对等式分布爬虫(Peer to Peer)
服务器来判断某个URL是否应该由自己来抓取,或者将这个URL传递给相应的服务器。
UbiCrawler爬虫:采用一致性哈希方法(Consisting Hash)来确定服务器的任务分工。
本章提要
- 从爬虫设计角度讲,优质的爬虫应该具备高性能、好的可扩展性、健壮性和友好性。
- 从用户体验角度考虑,对爬虫的工作效果评价标准包括:抓取网页覆盖率、抓取网页时新性和抓取网页重要性。
- 抓取策略、网页更新策略、暗网抓取和分布式策略是爬虫系统至关重要的4个方面内容,基本决定了爬虫系统的质量和性能。